
Быть программистом — значит выбрать путь непрекращающегося обучения, ведь это среда неиссякаемого потока нового — новые функции, новые языки, новые инструменты, новые фреймворки. Но в то же время компьютерная наука — это устоявшаяся область, базирующаяся на проверенных временем принципах. Мы привнесли в неё ООП, новейшее оборудование и искусственный интеллект. Но, несмотря на все эти изменения, многие идеи, зародившиеся десятилетия назад, до сих пор остаются актуальными.
В этой статье я раскрыл некоторые из моих любимых цитат, касающихся компьютерной науки. Единственным условием отбора было то, что цитата должна быть старше 20 лет. Т.к. несмотря на то, что технологии устаревают быстро, рекомендации программистов-первопроходцев хранят в себе куда больше остаточной силы.
1. О косвенной адресации
“В компьютерной науке все проблемы могут быть решены с помощью дополнительного уровня косвенности”, — Дэвид Уилер
Вот одна из часто повторяемых цитат, которую немногие разработчики любят объяснять. Однако она относится к моим любимым истинам программирования, т.к. раскрывает саму его суть.
Проще всего представить себе косвенность как слои. Например, у вас небольшой проект, который должен вписать компонент A в компонент B:
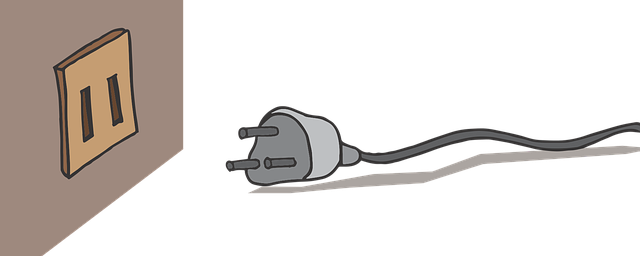 Части не подходят друг другу
Части не подходят друг другуОба компонента стандартизированы, поэтому вы не можете их разобрать и изменить. Вы могли бы создать компонент с нуля (PlugTwoProngVariant), но это потребует много работы и излишнее повторение. Лучшим выходом будет добавить слой между этими двумя частями — адаптер, который подойдёт обоим компонентам и соединит их.
Однако, если бы косвенность заключалась только в простом добавлении слоя для совмещения несовместимых вещей, то это было бы здорово, но мало где применимо. Тем не менее идея разрешения проблем с помощью внешних надстроек — это принцип, пронизывающий программирование от и до. Вы встречаете её, когда пытаетесь втиснуть новую модель данных в старый пользовательский интерфейс или, когда стараетесь добавить устаревшее приложение в новейшую службу бэкенда, или при необходимости добавить функционал более высокого уровня вроде журналирования и кэша, или чтобы скоординировать высокоуровневые сервисы вроде обмена сообщениями и транзакций. Ну и на самой вершине вы столкнётесь с этим в таких утончённых областях, как машинное обучение (если вы не можете задать нужное вам поведение, напишите дополнительный слой, который поможет решить проблему).
Многие скажут вам, что написание кода — это создание явных инструкций на языке, который поймут даже тупые компьютеры. Но цитата Дэвида Уилера раскрывает лучший подход. Хорошее программирование — это вскарабкивание по лестнице абстракций для получения более общих решений.
Сопутствующая цитата:
Косвенность — это мощь, и цена её — сложность. Люди очень редко цитируют вторую часть цитаты Уилера:
“Но как правило это создаёт другую проблему”, — Дэвид Уилер.
С тех пор эта истина удерживает программистов в деле (думал написать в седле, но что-то программист в седле…если только с ноутбуком:))).
2. О простоте
“Простота — это необходимое условие надёжности”,— Эдсгер Дейкстра.
Среди программистов всегда хватало мудрых людей, которые предупреждали нас не усложнять код. Но не многие смогли прояснить цену сложности так, как это сделал датский первопроходец компьютерной науки — Эдсгер Дейкстра.
Идея здесь в следующем: вы выбираете простоту не ради будущего и делаете это не потому, что предвидите необходимость повторного использования кода, или хотите, чтобы он выглядел чище во время ревью, или для облегчения его модификации (хотя всё перечисленное тоже важно!). Вы делаете это, потому что простота — это необходимое условие надежности. Без неё вам никогда не удастся создать надёжный код, которому можно доверить ведение бизнеса или обработку данных.
Чтобы принять точку зрения Дэйкстры, нам необходимо пересмотреть определение “хорошего кода”. Это не самый короткий и не обязательно самый быстрый и точно не самый умный. Это код, которому можно доверять.
Сопутствующая цитата:
Один из лучших способов сохранять код простым — помнить, что краткость — сестра таланта. Дейкстра разработал метрику, чтобы помочь нам в этом.
“Если мы посчитаем количество строк кода, то стоит рассматривать их не как “произведённые строки”, а как “строки потраченные”, — Эдсгер Дейкстра.
3. О читабельности и переписывании
“Код легче писать, чем читать”, — Джоэл Спольски.
На первый взгляд эта цитата легенды программного мира и сооснователя Stack Overflow — Джоэла Спольски выглядит правдивой, но обманчиво поверхностной. Да, код может быть плотным, немногословным и утомительно длинным. И это не обязательно чей-то код. Если вы взглянете на свой собственный, написанный с год назад, то наверняка затратите какое-то время прежде, чем проясните логику, которая тогда для вас была очевидна.
Однако в идее Спольски есть смысл. Опасность кода, который вы не можете прочесть, заключается не только в очевидном (его сложно менять и улучшать). В действительности большая опасность кроется в том, что сложный код кажется хуже, чем он есть на самом деле. И получается, что сложность понимания чужого кода настолько велика, что у вас может возникнуть желание совершить то, что Спольски называет худшей ошибкой, а именно — решить переписать код с нуля.
Я не хочу сказать, что переписывание не может улучшить архитектуру системы. Определённо это возможно. Но все эти улучшения будут достигнуты огромной ценой. Придётся заново проводить тестирование и устранять баги, т.е. выполнять две задачи, которые занимают куда больше времени, чем само написание кода. Склонность переписывать базируется на одном из основных заблуждений в среде разработки ПО: мы недооцениваем усилия, требуемые для создания принципиально простых вещей. Именно поэтому последние 5% проекта занимают 50% общего времени его разработки. Простые вещи могут требовать на удивление много времени. И ничто не выглядит проще решения проблемы, которую вы уже решали.
Тогда, если для достижения совершенства не стоит всё переписывать, то каково лучшее решение? Ответ заключается в распространении среди разработчиков проведения регулярного небольшого рефакторинга. Это даст постепенный и уверенный прирост в качестве кода — достойная награда при минимальных рисках. При этом вы можете попутно улучшать читабельность.
Сопутствующая цитата
Если вы всё ещё сомневаетесь в важности читабельности, то слова Мартина Фаулера помогут осознать ее более ясно:
“Любой дурак может написать код понятный для компьютера. Хорошие же программисты пишут код, который смогут понять люди”, — Мартин Фаулер
Другими словами, работа программиста заключается не в том, чтобы создать рабочую программу, но в том, чтобы сделать это осмысленно.
4. О повторах
“Не повторяйтесь. Каждый элемент знаний внутри системы должен иметь единственное, чётко выраженное и авторитетное выражение”, — Энди Хант и Дейв Томас.
Каждый уважающий себя программист знает, что повторяемость — это корень многих зол. Если вы повторно пишете одно и то же во многих местах, то увеличивается не только сам процесс написания, но также тестирование и отладка. Что ещё хуже, так это возможность появления несоответствий. Например, если одна часть кода обновляется, а другая нет, то возникает несогласованность схожих компонентов. В этом случае на итоговую программу уже нельзя положиться. А если на неё нельзя положиться, то и для применения она не годится.
 Этого бага можно было избежать с помощью метода getTeamUniform()
Этого бага можно было избежать с помощью метода getTeamUniform()Как бы то ни было, код не единственное место, где повторение нарушает ход вещей. Это версия известного правила “Не повторяйся” (DRY), которая расширяет этот принцип, не чтобы учесть и другие места, где могут таиться несоответствия. Мы уже говорим не о повторении кода. Теперь мы имеем в виду повторения в системе, которая имеет множество способов выражения знаний. Например, следующие:
- Инструкции кода.
- Комментарии кода.
- Документация разработчика или клиента.
- Схемы данных (например, таблицы баз данных).
- Другие спецификации вроде планов тестирования, документирования рабочего процесса и правил сборки.
Все эти группы могут пересекаться друг с другом, и если это происходит, то возникает риск привнесения различных версий одной действительности. Например, что случится, если документирование описывает один способ работы, а приложение при этом использует другой? Чему верить? Что случится, если таблицы баз данных не соответствуют модели данных в коде или если комментарии описывают операцию алгоритма, которая не совпадает с фактической реализацией? Каждая система должна иметь единое, авторитетное представление, из которого вытекает всё остальное.
К слову говоря, соперничающие версии правды являются проблемой не только малых проектов или плохо спроектированного кода. Один из лучших примеров, затронувший массовую общественность — это битва между XHTML и HTML5. Сторонники одного доказывали, что их спецификация является истинной и браузеры необходимо подстроить под неё. Их противники при этом заявляли, что поведение браузера было общепринятым стандартом, потому что именно так его представляли дизайнеры, когда прописывали веб-страницы. В итоге победила браузерная версия правды. С тех пор браузеры начали следовать HTML5, включая разрешённые ярлыки и допустимые ошибки.
Сопутствующая цитата
Возможность противоречий между кодом и комментариями породила горячие споры о том, что комментарии могут нести больше вреда, чем пользы. Сторонники экстремального программирования рассматривают их с нескрываемым подозрением.
“Код никогда не врёт в отличие от комментариев”, — Рон Джеффрис.
5. О трудном
“В компьютерной науке есть только две трудные вещи: недействительность кэша и именование”, — Фил Карлтон.
На первый взгляд эта цитата выглядит смешно, но она вполне ординарная шутка программистов. Контраст между тем, что звучит на самом деле звучит сложно (недействительность кэша) и тем, что звучит безобидно (именование) сразу же вызывает ассоциации. Каждый программист затратил множество часов на исправление до смешного простых проблем вроде пары параметров, переданных в неверном порядке или переменной, прописанной не в том регистре (спасибо, JavaScript). До тех пор, пока люди не перестанут зависеть от взаимодействия с машинами для выполнения различных задач, программирование будет представлять смесь высокоуровневого системного планирования и банальных опечаток.
Однако, если вы взглянете на цитату Фила Карлтона еще раз, то можете увидеть в ней больше. Именование вещей трудно не только потому, что жизнь программиста насыщена регулярными мелкими головными болями, но также и потому, что проблема именования — это краеугольный камень наиболее важной части работы любого разработчика — дизайна ПО. Иначе говоря, того, как вы создаёте понятный, чистый и согласующийся код.
Есть множество способов ошибиться в использовании имён. Мы все видели переменные, названные согласно типам данных (myString, obj), в виде аббревиатур (pc для product catalog (каталог продукции)), или обыденных деталей реализации (swappable_name, formUserInput), или просто таких ret_value, tempArray. Легко угодить в подобную западню присвоения имён переменных, если делать это на основе производимых с ними действий, а не их содержимого. При этом логические значения особенно хитры — подтверждает ли progress начало прогресса, необходимость отражения прогресса в UI или что-то совсем другое?

Однако имена переменных — это лишь вершина айсберга. Именование классов поднимает вопрос о том, как вы разделяете код на независимые части. Именование публичных членов описывает, как вы представляете интерфейс, позволяющий одной части приложения взаимодействовать с другой. Закрепление этих имён не только описывает, что часть кода может делать, но также и то, что она будет делать.
Сопутствующая цитата:
“В компьютерной науке есть две трудные вещи: недействительность кэша, именование вещей и ошибки на единицу”, — Леон Бамбрик.
Специально для сайта ITWORLD.UZ. Новость взята с сайта NOP::Nuances of programming