
В данном конкурсе, проводимом в рамках отборочного тура VK Сup 2020, трек ML, необходимо было предсказать долю потенциальной аудитории, которая просмотрит рекламные объявления, показываемые на нескольких рекламных площадках конкретное число раз: 1,2,3 еще и в будущем.
Это было не классическое соревнование по отправке итоговых предсказаний на известные тестовые данные, а предсказание на полностью неизвестных данных, подаваемых на работающую модель в докер образе, запущенном на площадке конкурса.
В целом, такое решение уравнивает шансы участников и не позволяет тем, кто любит подглядывать в тест, обогащать им тренировочный набор данных, подгонять модель под распределение тестовых данных. Здесь все были в равных условиях, так как не понятно, что может быть в данных: “мусорные” данные, спорадические выбросы, неверные разделители и прочее. Но все эти нюансы одновременно заставляют думать и об обработке исключений.
В этом конкурсе я занял непочетное 4 место и хочу рассказать, как же это удалось.
Обзор данных
Исходные данные были представлены в следующем виде:
- Файл users.tsv – содержит информацию о пользователях: пол, возраст, город проживания. Соответственно этим пользователям и показывались объявления, как в текущей истории, так и в будущем, это было гарантированно организаторами в описании задачи. Учитывая большое число пропусков в данных и неоднозначные результаты на валидации (при добавлении этих данных), я полностью отказался от их использования.
- Файл history.tsv — содержит комбинации "пользователь-площадка", просмотр объявления за указанную цену в конкретный час (указан сквозной нумерацией) по историческим данным. То есть данный файл представлял собой статистику просмотров в прошлом, а как уже было сказано выше, оценивать новые данные мы должны на следующем интервале времени.
- Файл validate.tsv — валидационный файл для тренировки модели, в нем как раз были данные о том, в какой интервал времени и по какой цене было показано объявление для конкретной аудитории (площадка и пользователь). Пользователи и площадки приводились в строковой форме вида (1,5,7,3,14,6).
- Файл validate_answers.tsv — файл ответов, состоящий из трех колонок: какая доля (значения от 0 до 1) аудитории посмотрит объявление 1, 2, 3 раза. Соответственно последовательности эти не возрастающие.
Цель конкурса: на новые данные из будущего (в формате файла validate.tsv) предсказать три набора значений — какая доля аудитории посмотрит объявление 1,2, 3 раза.
Более подробно о задаче на сайте конкурса.
Предикторы
Итоговые предикторы которые я использовал, представляют собой набор из 2 комплексов:
- предикторы на основе истории и их сопоставления с новыми данными
- предикторы только на данных из будущего
Среди первого комплекса, на основе файла истории, по сгруппированным парам «пользователь-площадка» были сгенерированы базовые статистики, и в дальнейшем их агрегация на пару «пользователь-площадка» в валидационном и тестовом файле. Далее следовал отбор предикторов разными способами — как исходя из частот использования предикторов на этапах разбиения и использования в самой модели, так и на валидациях, сверху вниз и снизу вверх. Несмотря на разные схемы отбора, в целом все сводилось примерно к одному набору предикторов и в итоге их оказалось семь.
Трактовка предикторов второго комплекса (их тоже на удивление оказалось семь) в целом гораздо проще:
1. Delta — разность времени. Логично? Логично: чем больше интервал, тем вероятно больше просмотров. Конечно, зависимости прямой нет, но физически должно быть именно так, более того это один из самых сильных предикторов, если рассматривать их по отдельности.
2. Delta2 — тоже разность времени, но переведенная в сутки (то есть целочисленное деление на 24). То есть линейную зависимость мы превращаем в кусочную. Идея здесь простая: мы не делаем различий между часами, но вот очень длительные интервалы (сутки) будут задавать свой тренд.
3. cpm — непосредственно цена, аналогично: чем дороже цена, тем более вероятен просмотр, опять же, зависимости прямой конечно нет, но в «заигрывании» с другими предикторами на основе истории, зависимость явно выслеживается.
4-7. Это sin и cos времен начала и конца показа объявлений, переведенных также в 24 часовую шкалу. Использование данных функций, в отличие от линейного времени, позволяет учесть временные интервалы, переходящие через сутки. Применение этих предикторов сразу дало улучшение на 1.5 п.п.
Метрика и отклик
Представленная организаторами метрика конкурса Smoothed Mean Log Accuracy Ratio (далее SMLAR).

Где исходный отклик представлен в доле аудитории, которая просмотрела объявление 1,2,3 раза, то есть значения в диапазоне [0,1].
Кстати, на КДПВ указано поведение данной метрики, вернее не целиком метрики, а ее части (MAE на логарифм смещений предсказаний) при всех комбинациях предсказания и истинного значения на всем диапазоне [0,1].
Если внимательно посмотреть на формулу метрики, то: с одной стороны, данная метрика примерно соответствует среднегеометрической средней отношений предсказаний и истинного значения (со смещением), что явно лучше, чем среднеарифметическая метрика (по причине более низкого итогового результата). С другой стороны, если опустить экспоненту, которая на малых значениях ведет себя почти как сам показатель ее степени, метрика трансформируется в MAE на логарифм отклика со смещением. Таким образом, для построения идеологически верных моделей необходимо было использовать в построении модели исходный отклик со смещением и ту функцию потерь, в которой в явном виде есть логарифмирование, или же, наоборот, предварительно использовать логарифмирование отклика со смещением и линейную функцию потерь (MAE, eps). Но, учитывая мою модель (в которой в явном виде не задается функция потерь), оптимальную трансформацию отклика я выбирал исходя из результатов модели на валидации.
Мной были рассмотрены следующие варианты отклика – оригинальные доли, логарифмирование долей, переход к абсолютным значениям количества пользователей, их логарифмирование с различными смещениями (здесь была попытка использовать одно унифицированное смещение при переходе к абсолютным значениям, так как смещение 0.005 указано для долей, а аудитория была разной, от 300 до 2500, поэтому смещение должно быть в границах от 1 до 12, но я проверял только значения 1 и 10), и корень из абсолютного значения людей просматриваемых объявление.
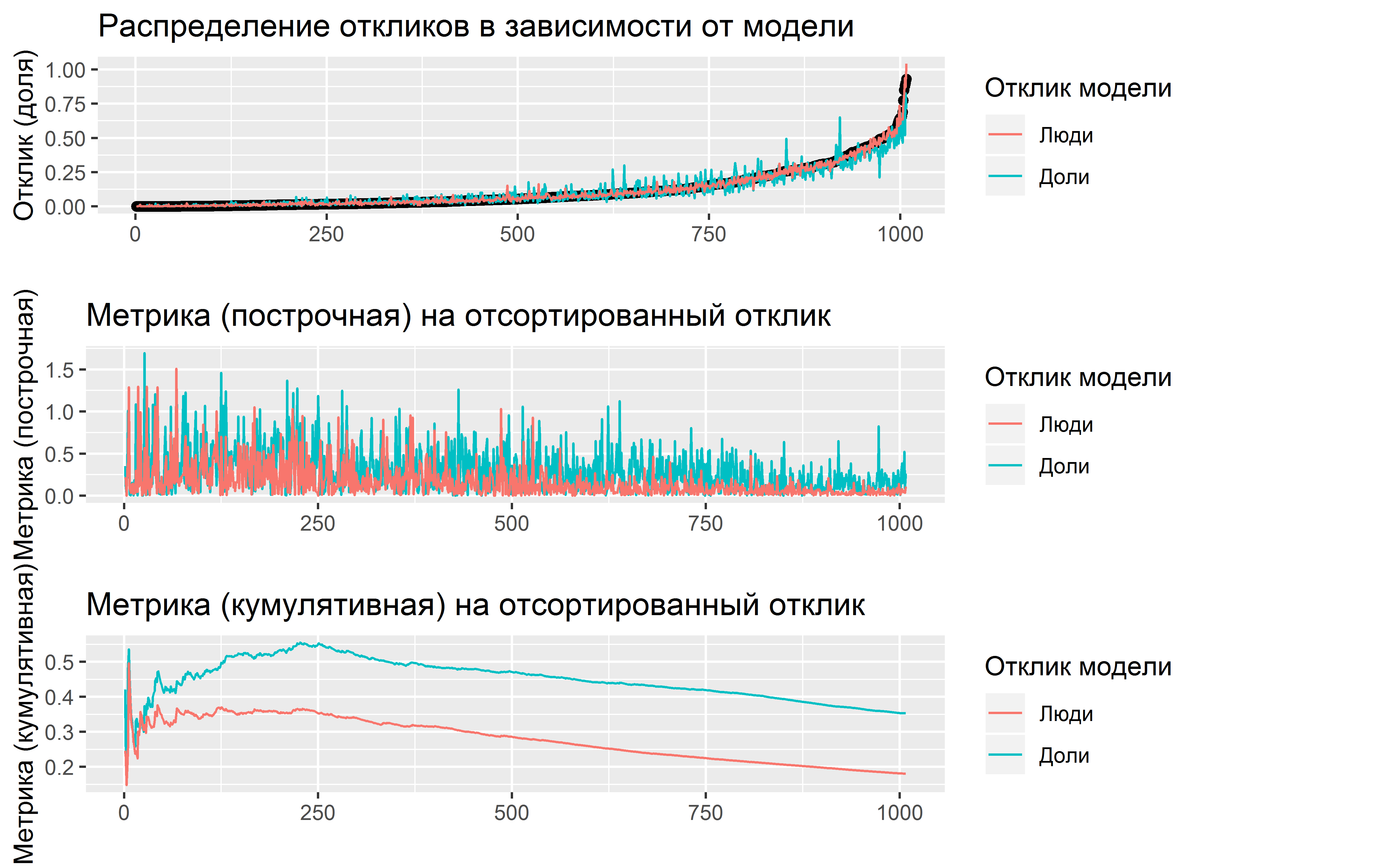
На картинке выше приведены результаты по двум моделям, которые тренировались на разный отклик: на исходные доли аудитории и на абсолютное число участников.
На верхней диаграмме приведены отсортированные значения истинного отклика (по долям первого просмотра) и предсказанные значения по обоим моделям. Сразу видно, что большая часть значений отклика достаточно малая, так медианное значение около 5%, и это только для первого просмотра (для второго просмотра медиана уже менее 1%, а для третьего практически 0%, а для данной метрики малые значения и ошибки на них это весьма неприятно). Также на данной диаграмме явно видно, что модель на абсолютные значения качественно лучше, разброс по оценкам достаточно минимальный, и, несмотря на то, что визуально на графике на малых значениях отклонения почти не видны, в итоге именно ошибки на этих малых значениях сильно влияют на итоговый результат. Это же видно и на КДПВ, очень резкая кривизна на малых значениях, особенно близких к нулю.
На средней диаграмме показана ошибка каждого отсортированного предсказания, видны сильные ошибки на малых значениях и уменьшение их с увеличением значений отклика.
На нижней диаграмме уже строится диаграмма непосредственно целевой метрики накопленным итогом по всем отсортированным значениям. Какие же выводы из всего этого? Первый это то, что выбранный отклик сильно влияет на результаты модели, но об этом ниже, второй вывод, особое внимание обращать на малые значения, особенно близкие к нулю, очевидно, что модели не всегда смогут предсказывать чистый нуль, поэтому необходимы корректировки. А ошибки на больших значениях не так важны, во-первых, их относительно мало, во-вторых, процентная ошибка на больших значениях будет мала, и при этом она внесет минимальный итоговый вклад в метрику.
В итоге, по результатам многочисленных экспериментов, победителем с явным отрывом оказался отклик — корень из абсолютных значений пользователей. При этом на разных предсказаниях (на 1, 2, 3 просмотра), иногда побеждали и модели с логарифмированием абсолютных значений, это связано с явным преобладанием 0 в откликах, и, как следствие, логарифмирование с каким-то смещением подходило лучше. Но если оценивать в среднем, то простой корень без всяких смещений показывал хорошие стабильные результаты, поэтому хотелось не усложнять решение, а остановиться на простом унифицированном способе — просто корень из людей.
Чем обусловлено то, что переход к людям значительно улучшает результат относительно долей (почти в 2 раза)?
Видимо дело в том, что переходя к людям, домножая долю на аудиторию, или что тоже самое, что деля все предикторы на эту же аудиторию, мы переходим в размерность относительно «одного человека», а учитывая, что в основе моей модели — регрессии, итоговая оценка есть некая взвешенная оценка вероятности относительно каждого предиктора. Вполне возможно, что если нормировать на аудиторию только часть предикторов, например, из предикторов первой группы (сумма по всем парам, например), то это нормировка тем самым приближала бы размерности всех предикторов к единой системе отчета (на одну персону), и итоговая регрессия, ее отклик, была бы не что иное, как средневзвешенная сумма вкладов каждого предиктора (которые и характеризуют одного человека) на итоговую вероятность просмотра, то возможно и результат был бы лучше. Но на момент решения конкурса с этой стороны я не подходил и работал исключительно с трансформированным откликом.
Модель
На самом деле данный раздел необходимо было ставить выше, так как именно из-за этой модели, приходилось подбирать вид отклика и необходимые используемые предикторы под него (модель подстраивалась под данные) и, так или иначе, даже на разных предикторах можно было выйти на приемлемый результат около 15%. Но мне хотелось, чтобы именно в среднем было какое-то обоснование выбора конкретных предикторов, поэтому на валидации и отбирались комбинации предикторов.
Мной использовалась модель из семейства деревьев регрессионных моделей, а именно модель cubist (модель 1992! года), и ее реализация в одноименном пакете в R. Вернее, итоговый результат это среднегеометрическая средняя двух наборов моделей, каждый из которых состоял из 3 отдельных моделей, но каскадом: предсказание предыдущей модели (на 1 просмотр) использовалось как предиктор для второй и третьей модели, а итоговое предсказание на второй просмотр как предиктор на третью модель. Обе пары моделей отличались немного предикторами и промежуточными корректировками, а их среднегеометрическая средняя использовалась исходя из здравого смысла (ну и валидации, с пабликом конечно), а смысл здесь простой: как выше мной писалось, особое внимание на нулевые предсказания, да и вообще на минимальные, а среднегеометрическая средняя именно это и делает: обращает в нуль предсказание, если одно из них уже нулевое (и это логично, если одна из моделей показала нуль, так пусть он и остается, чем мы будем «оттягивать» предсказание от нуля).
А благодаря каскаду моделей, модель опосредованно “понимала” (так как регрессии), что каждый следующий отклик «цепляется» за этот ранее предсказанный ответ предыдущей оценки, а остальные предикторы корректируют ответ, который должен быть не больше предыдущего. Также мной проверялись и три отдельные модели, предсказывающие отклики по отдельности. Результат был слабее из-за обилия нулей при вторых и третьих просмотрах, семейство регрессий не могло достаточно точно уходить в 0, а когда мы добавляем «поводыря» предыдущей оценки, которая уже 0 или близка к нему, получаемое семейство регрессий также падает в окрестность данного значения и корректирует лишь отклик на второй и третий просмотр.
Чем же хороша данная модель?
Увидев задачу я сразу вспомнил про данную модель, так как на одном из предыдущих конкурсов в сопоставимой задаче (линейные связи и их корректировки) она оказалась также одной из лучших, да и в целом, у нас здесь достаточно линейные данные, есть явная зависимость между количествами просмотров (второй меньше первого, третий меньше второго), данных немного — всего 1008 наблюдений, есть небольшое число предикторов, вероятно какие-то линейные-ломаные зависимости. К тому же данная модель очень быстра, построение занимало несколько секунд, поэтому ей было удобно тестировать многие гипотезы. Да и еще, у нее нет гиперпараметров (за исключением соседей (еще один параметр корректирующий прогноз), который я не использовал), на которых можно было бы переобучиться.
Более подробно о данной модели, критериях расщепления, сглаживании предсказаний можно посмотреть в презентации авторов пакета или же в публикациях авторов на сайте.
Корректировки
Дополнительно использовались небольшие корректировки предсказаний, а именно: при переходе от абсолютного числа людей к их долям потенциально возникали ситуации очень малых значений (положительные, чуть более 0, или больше 1), и если в случае значений больше 1, их корректировка не играла большей роли (вероятно таких перелетов было мало, а если и были, то не значительные), то вот в случае малых значений, это было относительно критично. Путем рассуждения было принято, что если я предсказываю например 1 человека (или 0.5 человека, округления не осуществлялось), то при максимальной аудитории в 2500 (это при известных данных в трейне, что реально происходит на тестовых данных, совершенно не известно), что составляет 0.0004 (кстати и в трейне, минимальное значение 0.0004), значит где-то в окрестностях этого значения необходимо меньшие значения обращать в 0, а учитывая, что у меня модели построены цепочкой, и от предсказанного нуля зависит построение следующей модели и ее предсказаний, и т.д. это влияло достаточно сильно.
Подбирать порог на валидации смысла особо не было (т.к. модель и так подстраивается под эти данные, да и я знаю распределение), поэтому поглядывал на паблик (для некоторых подбираемых значений), но в итоге все равно для одной тройки моделей я оставил красивый порог округления в 0.0005, а для второй теоретические 0.0004.
Корректировка сверху была проще, значения больше 0.95 обращать в 0.95, 0.95 было принято исходя из максимальной доли в тестовых данных, с большим запасом (в трейне максимум 0.93), эта корректировка практически не влияла на паблик (единичные вылеты видимо в паблике), оставил исключительно для безопасности на приват. И еще была добавлена корректировка, связанная с нулями, если на первом просмотре предсказание нулевое, то несмотря на предсказания моделей на втором и третьем просмотре, их предсказания тоже уходят в 0, это влияло не сильно, где-то второй знак (все же модель практически всегда и так сама это (меньше предыдущего и к нулю) делала), но оставлено для безопасности на привате.
Результаты
Результаты очень зависели от выбранного типа отклика и отобранных предикторов, например, даже если предсказывать доли, или что еще лучше их логарифм, то можно было отобрать другие предикторы и результат был бы около 16%, а если перейти к абсолютным значениям и также переотобрать предикторы, то там уже все начиналось около 15%, поэтому это и стало моим бейзлайном.
И кстати этих результатов было уже достаточно чтобы остаться в пятерке лидеров, но интересно было «повыжимать» побольше.
И так, что же резко улучшило эти 15%?
В общем-то, только добавление часов, просто часов (время начала и конца), сразу дало 13.97%, изменение их на синусы-косинусы улучшило до 13.44%, ну а дальше улучшение до 13.25% было округлением малых значений в нуль, и среднегеометрическая средняя двух моделей, то есть это уже было больше тюнинг под тест (паблик), и из-за этого я все-таки немного переподогнался под паблик.
В этом конкурсе необходимо было выбрать одно решение. Сейчас, поглядывая в ЛК, вижу, что мое выбранное решение, оказалось почти лучшим и на привате (место не изменилось) (лучший приват меньше на 0.02 п.п.), но если брать отправки в которых не так округлялся ответ, то на привате они были чуть хуже — 13.6%, то есть и сильного переобучения под паблик не было, но и очень большой роли весь этот посттюнинг и не играл.
В итоге основной задел успеха: предикторы, отобранные под выбранный отклик, модель cubist, каскад моделей(1->2->3) и временные предикторы (sin, cos).
Заключение
Несмотря на то, что призеры первых пяти мест использовали различные модели, в том числе и современные (1 место – SVR, 2 место – catboost, 3 место – neural net, 5 место – lightgbm, хотя у этих призеров были гораздо более сложные предикторы), я занял 4 место используя одну из старейших, классических моделей 1992 года (даже идеи SVR появились позже) на достаточно простых и очевидных предикторах, что еще раз подтверждает: не всегда достаточно бустить на сгенерированных предикторах (эти подходы были сильно ниже в итоговом рейтинге, около 20%), здесь играет значительную роль и здравый смысл предикторов, и трансформация отклика, и выбор функции потерь в моделях (при наличии).
В целом, конкурс получился интересным и творческим, с соответствующими выводами.
Надеюсь, на финальном (очном) этапе конкурса задача будет не менее интересной.
Специально для сайта ITWORLD.UZ. Новость взята с сайта Хабр