Приходилось ли вам обрабатывать с помощью Node.js одновременно миллионы строк базы данных и выводить всё это на веб-страницу? Это непросто, но у нас есть готовое решение.

Попробуем решить описанную проблему со следующим стеком технологий:
- Node.js
- Sequelize (ORM-библиотека, основанная на промисах)
- MariaDB
Что на клиенте – не имеет значения. Когда размер данных приближается к 4 Гб, Chrome в любом случае упадет.
Потоки
Очевидное решение проблемы большого объема данных – потоковая передача. Если вы попробуете отправить их одним большим куском, Node не справится.
Тут возникает первая большая проблема – Sequelize не поддерживает работу с потоками.
Вот так выглядит классический вызов библиотеки:
await sequelize.authenticate();
const result = await sequelize.query(sql, { type: sequelize.QueryTypes.SELECT });
res.send(result);
Конечно, тут кое-что пропущено – вроде конфигурации базы данных и собственно определение вызова метода get() (откуда, например, приходит res?). Но вы, безусловно, разберетесь в этом самостоятельно.
Результат работы этого кода вполне предсказуем – Node падает. Вы можете, конечно, выделить больше памяти – max-old-space-size=8000, но вряд ли это можно назвать решением проблемы.
Попробуем вручную реализовать потоковую передачу данных:
var Readable = stream.Readable;
var i = 1;
var s = new Readable({
async read(size) {
const result = await sequelize.query(
sql + ` LIMIT 1000000 OFFSET ${(i - 1) * 1000000}`, { type: sequelize.QueryTypes.SELECT });
this.push(JSON.stringify(result));
i++;
if (i === 5) {
this.push(null);
}
}
});
s.pipe(res);
В этом примере мы знаем, сколько строк вернется из базы данных, отсюда строка if (i === 5). Это просто тест. Чтобы завершить поток, вы должны отправить null. Можно заранее получить значение count (количество строк).
Основная идея состоит в разделении одного большого запроса на несколько маленьких и потоковое получение отдельных чанков. Это работает, Node не падает от перегрузки, но работает очень долго. 3.5 Гб данных вы будете обрабатывать примерно 10 минут!
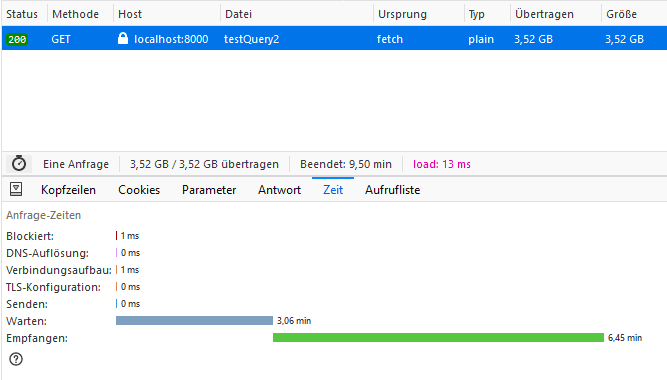
Нет ли другого – более быстрого – решения?
Коннектор для базы данных
Есть – это неблокирующий клиент MariaDB Node.js connector.
Вот так выглядит обычный запрос:
const mariadb = require('mariadb');
const pool = mariadb.createPool({ host: "HOST", user: "USER", password: "PASSWORD", port: 3308, database: "DATABASE", connectionLimit: 5 });
let conn = await pool.getConnection();
const result = await conn.query(sql);
res.send(result);
Он уже достаточно быстрый, однако попробуем потоковый код:
let conn = await pool.getConnection();
const queryStream = conn.queryStream(sql);
const ps = new stream.PassThrough();
const transformStream = new stream.Transform({
objectMode: true,
transform: function transformer(chunk, encoding, callback) {
callback(null, JSON.stringify(chunk));
}
});
stream.pipeline(
queryStream,
transformStream,
ps,
(err) => {
if (err) {
console.log(err)
return res.sendStatus(400);
}
})
ps.pipe(res);
Выглядит загадочно, но тут не происходит ничего сложного. Мы просто создаем пайплайн для данных:
- Поток
queryStream– результат запроса к базе. - Поток
transformStream– для отправки преобразованных в строки чанков (здесь можно использовать только строки и буферы). - Класс stream.PassThrough это реализация трансформирующего стрима.
- Функция для обработки ошибок.
ps.pipe(res) – отправляет результаты обработки клиенту.
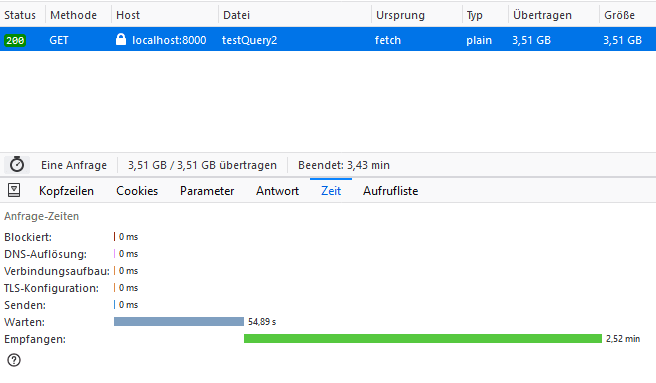
Это решение работает гораздо быстрее – те же данные передаются меньше, чем за 4 минуты без перегрузки Node.
Результат
Итак, если вам приходится работать с огромным количеством данных, у вас есть три пути:
- Использовать потоковую передачу.
- Подумать о введении пагинации – получать данные небольшими кусками.
- Убедить клиента, что в условиях современного веба это невозможно.
Как вы решаете подобные задачи?
Источники
Специально для сайта ITWORLD.UZ. Новость взята с сайта Библиотека программиста