
Картинка, которую вы видите, позаимствована с сайта DeepMind, и демонстрирует 57 игр, в которых их новейшая разработка Agent57 (обзор статьи на Хабре) достигла успеха. Само число 57 взято не с потолка, — именно столько игр было выбрано еще в 2012 году, чтобы стать своеобразным бенчмарком среди разработчиков ИИ для игр Atari, после чего различные исследователи меряются своими достижениями именно на этом датасете.
В этом посте я постараюсь с разных сторон посмотреть на эти достижения, чтобы оценить их ценность для прикладных задач, и обосновать, почему не верю, что за этим будущее. Ну и да, картинок под катом будет много, — я предупредил.
В приведенной выше ссылке разработчики пишут правильные вещи, говоря, что
So although average scores have increased, until now, the number of above human games has not. As an illustrative example, consider a benchmark consisting of twenty tasks. Suppose agent A obtains a score of 500% on eight tasks, 200% on four tasks, and 0% on eight tasks (mean = 240%, median = 200%), while agent B obtains a score of 150% on all tasks (mean = median = 150%). On average, agent A performs better than agent B. However, agent B possesses a more general ability: it obtains human-level performance on more tasks than agent A.
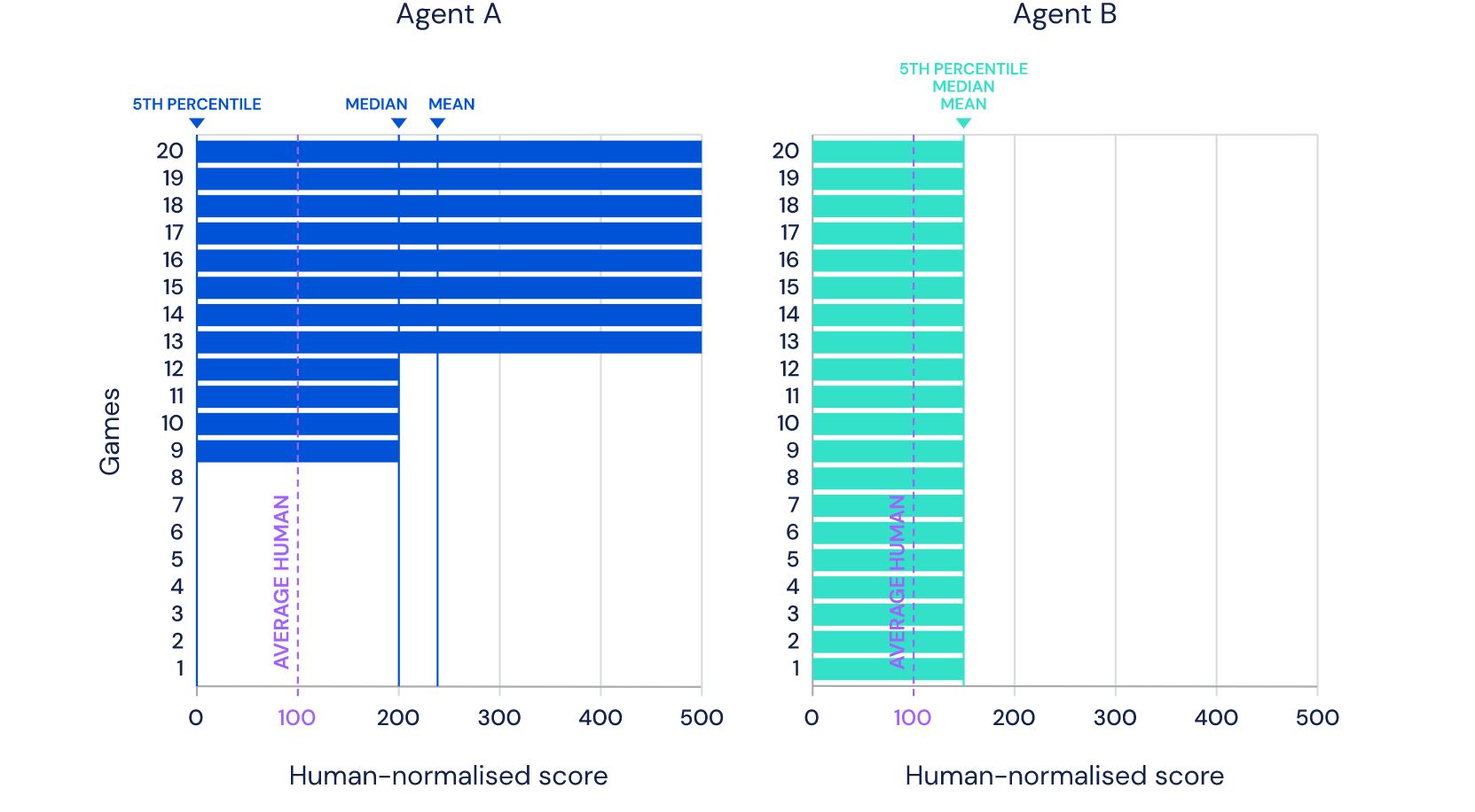
Что на пальцах означает, что раньше все мерялись в зачете «по среднему», отмахиваясь от сложных для компьютера кейсов, а сейчас занялись как раз ими. И таким образом достигли реального превосходства над человеком, а не сверхрезультатов на «удобных» для копьютера кейсах.
Но давайте посмотрим на задачу глобальнее, чтобы понять, так ли это.
Что представляет собой взаимодействие ИИ DeepMind с видеоигрой
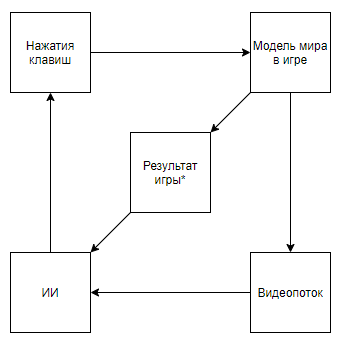
Звездочкой тут и далее будут обозначены обозначены сущности, полученные алгоритмом, созданным не при помощи ИИ, а при помощи экспертного мнения.
Перед тем, как разбирать схему, посмотрим на альтернативный подход:
- Делаем эмулятор модели мира в игре
- Отдаем боту готовые фичи + результат игры, а наблюдателю видео
- Обучаем ИИ на основе этих готовых фичей и результата игры

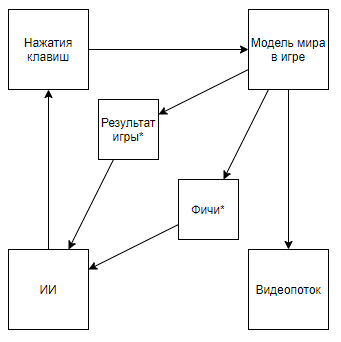
Схема становится вот такой. И если полазить по каналу автора, то можно найти ее применение и к ретро играм. Поменяв схему на такую, мы приходим к тому, что скорость и эффективность обучения растет на порядки, но при этом научная и инженерная ценность достижений такого похода становится близкой к 0 (и да, — я не беру во внимание популяризаторскую ценность).
Можно предположить, что все дело в том, что из пайплайна выбрасывается видео, но рассмотрим следующую схему (уверен, что кто-то реализовал нечто подобное, но под рукой нет ссылки):
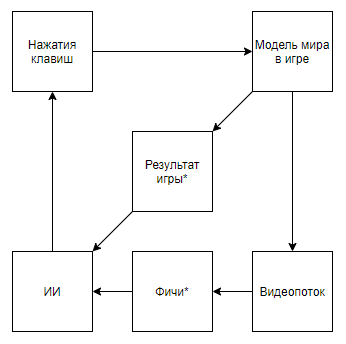
Которая реализуется, когда эксперт, знающий необходимые фичи, пишет парсер видеопотока, который по ключевым пикселям рассчитывает фичи.
Или даже вот такую схему:
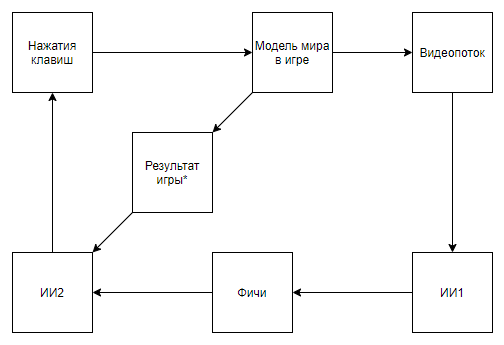
Где сначала ИИ1 обучают извлекать из видео избранные экспертом фичи.
А потом ИИ2 учат играть по фичам, извлеченным из видеопотока при помощи ИИ1. Вот мы и получили схему, которая
- Использует видеопоток, и не имеет прямого доступа к модели мира
- Не опирается на написанные экспертом парсеры видеопотока
- Будет обучаться в разы проще и эффективнее, чем разработки DeepMind
Но… мы приходим к тому же. Такая реализация, снова таки, не будет иметь ни научной, ни инженерной ценности в контексте применения к ретро-играм так, как ИИ1 — это давно решенная и весьма примитивная для современных алгоритмов обработки изображений задача, а ИИ2 тоже создается очень быстро и просто, что подтверждает автор приведенного выше видео.
Итого, а в чем же ценность алгоритмов DeepMind для игр Atari? Попробую обобщить: ценность в том, что алгоритмы DeepMind способны находить оптимальную стратегию поведения для игр с примитивной моделью мира MM в условиях, когда состояние модели мира S(MM, t) представлено со значительными искажениями некой искажающей функцией F(S(MM, t)), оценивать качество принятых решений можно только функцией, которая принимает на вход последовательность значений F(S(MM, t)) и реакций алгоритма, причем эта последовательность неизвестной длинны (игра может окончится за различное количество шагов), но при этом можно повторять эксперимент бесконечное число раз.
Теперь попробуем оценить применимость такой ценности для решения задач реального мира, которые хоть как-то соотносятся с инструментарием, а именно, — представляют реальное состояние со значительными искажениями, подразумевают, что окружение реагирует на действия агента, дают оценку только после длительной последовательности решений, и при этом позволяют проводить эксперимент много раз.
На первый вгляд, интересным применением кажется игра на бирже. Даже подсказки Гугла, выдавая его единственной подсказкой с применением в реальном мире, намекают, что тема горячая.
Сразу обозначу важный момент, — почти все подходы по анализу рынка (не считая подходов, анализирующих объекты реального мира, как парковки перед супермаркетами, новости, упоминания акции в твиттере) можно разделить на два типа. Первый тип, — это подходы, представляющие рынок, как временной ряд. Второй, — как поток заявок.
Но принципиальная разница не в используемых данных, а в том, что, как правило, анализирующие рынок, как временной ряд, пренебрегают своим влиянием на рынок, считая, что, условно, на дневном интервале, их сделки никак не повлияют на дальнейшую динамику рынка. В то время, как сторонники второго подхода могут как пренебрегать, считая, что их объем незначителен по отношению к ликвидности рынка, так и рассматривать рынок, как систему с обратной связью, считая, что своими действиями влияют на поведение других игроков (например, это касается исследований и подходов, связанных с оптимальным исполнением крупных ордеров, маркет-мейкингом, High-frequency trading).
Просмотрев поисковую выдачу, видно, что все статьи и посты посвященные трейдингу при помощи обучения с подкреплением (наиболее близкая тема к успехам DeepMind) посвящены первому подходу. Но возникает резонный вопрос о соразмерности подхода задаче.
Для начала нарисуем схему по аналогии с играми Atari
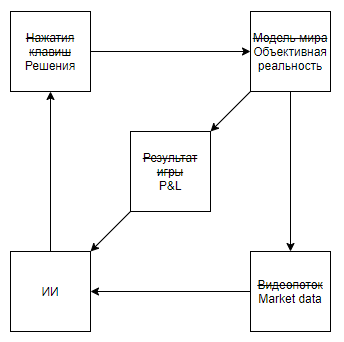
Вроде все ложится красиво. И, подозреваю, что это сходство и разогревает хайп. Но, что, если схему чуть уточнить:
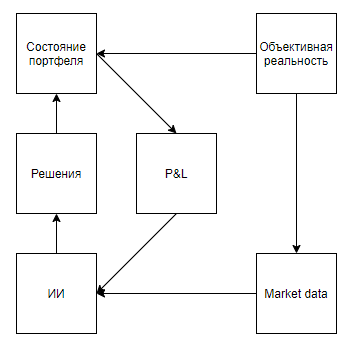
Стоит вынести состояние портфеля (сколько бумаг и денег на счету в каждый момент времени, а также, — сколько это все стоит) из блока «объективная реальность», как большой цикл обратной связи исчезает, и киллер-фича обучения с подкреплением становится невостребованной. Можно долго спорить о том, что ну и что, что используется инструмент, заточенный под системы с сильно более сложной структурой, — более общий AlphaZero же побил специализированный AlphaGo. Но тут рискну предположить, что не тот случай. Ведь происходит невероятное раздутие рамерности и сдутие датасета. Ведь, если у нас есть, например, временной ряд на 10000 точек, то вместо того, чтобы провести обучение, как принятие ~10000 решений, мы ограничены оценкой одного решения (множества сделок) целиком, тем самым, лишив себя защиты от оверфиттинга. Так что, условие о возможности производить много экспериментов не выполняется. Хотя, если ограничиться научным. а не коммерческим применением, то там можно нагенерировать сколько угодно временных рядов, абстрагировавшися от реального рынка, и подход вполне может принести профит (правда, не за счет прибыли на рынке, а за счет выступлений и публикаций в научной среде).
Второй подход (с потоком заявок) выглядит более перспективным. Так называемый стакан часто наполнен заявками роботов, которые охотятся за долями процента от цены, соревнуясь в месте в очереди, и часто создавая заявки только для того, чтобы сделать видимость спроса или предложения, и спровоцировать других ботов на невыгодные действия. Казалось бы, если пофантазировать, то что, если создать эмулятор биржи, и в нем поселить HFT ботов, которые, принимая миллиарды решений, будут самообучаться, играя с клонами самих себя, и тем самым, выработают идеальную стратегию, которая будет учитывать все оптимальные контрстратегии… Жаль, что, если что-то такое и произойдет, то об этом узнает человек 5 во всем мире, — деловые принципы высокочастотных трейдеров подразумевают абсолютную секретность, и отказ от публикации даже неудачных результатов, чтобы оставить врагам шанс наступить на те же грабли.
Думаю, особо не стоит заострять внимание на невозможности применения подобных подходов в маркетинге, HR, продажах, менеджменте и других сферах, где объектом выступает человек, ведь, для корректного применения надо дать возможность ИИ совершить миллионы, а то и миллиарды экспериментов. И, если даже у многих компаний и наберется миллион взаимодействий с объектом, где ИИ может принять решение (выбор баннера для показу потенциальному клиенту на основе его профиля, решение об увольнении сотрудника), то ни у кого не наберется миллион экспериментом с одним и тем же объектом, что именно и требуется для качественного применения. Но на чем стоит заострить внимание, — так это на антифроде и кибербезопасности.
Не знаю, к счастью, или к сожалению, но в современном мире очень многие экономические взаимоотношения строятся на предоставлении небольшой ценности без обязательств в обмен на ожидание большой ценности в будущем, — что порождает многочисленные источники халявы, и потенциал для фрода.
Примеры:
- Первая бесплатная поездка в аггрегаторах такси
- Выплаты в $70 по СРА в гемблинге, за игрока, который занес $5
- Тестовые $300 у облачных провайдеров и триал периоды
Более того, фродовый потенциал современной экономической системы подкрепляется низкой степенью защиты операций по кредитным картам, — ведь мерчанты часто целенаправленно отказываются от того же 3D secure для упрощения пользовательского опыта. Таким образом, для покупателей ворованных карт за небольшой % от их баланса, можно дополнять этот список почти до бесконечности.
Основная же проблема в борьбе с подобными кейсами лежит в невозможности собрать датасет достаточного объема, — % фродовых операций на 1-6 порядков ниже процента хороших операций в зависимости от бизнеса. А так же проблема в гибкости фродеров, которые с легкостью обходят статичные алгоритмы, подстраиваясь под антифрод-системы, обученные на прошлом опыте.
И, казалось бы, вот оно. Алгоритмы, подобные Agent57, запущенные в песочнице, позволят создать идеального фродера, постоянно актуализировать его навыки, и при этом решать обратную задачу, — держать актуальным и алгоритм для его выявления. Но есть один нюанс. Выиграть у модели мира, заложенной в игры Atari, — совсем не то же самое, что выграть у антифрод системы, уже обученной на основе поведения миллионов игроков, да и множество действий при фроде несоразмерно множеству действий игрока в ретро-игре. К примеру, даже такое простое действие, как ввод логина на форме регистрации уже несет под собой миллиарды вариантов сделать это. Начиная от того, какой юзер агент передать серверу, и заканчивая тем, сколько миллисекунд ждать между вводом второго и третьего символа логина…
Вообщем, я это все вижу как-то так. Довольно безрадостно. И очень надеюсь, что неправ, и где-то что-то не учел в модели. Буду благодарен, если увижу контрпримеры в комментариях.
Only registered users can participate in poll. Log in, please.
А вы верите в практическое применение подходов из Agent57?
-
12.5%Да, будущее есть!1
-
50.0%Нет, просто дорогая игрушка!4
-
37.5%Как-то все равно3
-
0.0%Оно уже наступило0
Специально для сайта ITWORLD.UZ. Новость взята с сайта Хабр