У него не было уверенности, что он правильно расслышал. От этого так много зависело! Но не переспрашивать же? (с) Борис Акунин. Весь мир театр.
Работая над голосовым помощником, который упоминается в предыдущей статье, понял, что просто не могу с вами не поделиться прекраснейшей библиотекой FuzzyWuzzy.
Если коротко, то благодаря ей существует возможность произвести нечёткое сравнение строк без каких-либо страданий.
Первые шаги
Для начала работы необходимо проделать два шага:
/ВАЖНО! Версия Python 2.7 и выше/
Шаг 1. Установка.
Открываем командную строку и вписываем:
pip install fuzzywuzzy
Нажимаем Enter.
Далее устанавливаем таким же образом python-Levenshtein для ускорения сопоставления строк в 3-10 раз.
pip install python-Levenshtein
После завершения установки библиотека готова к импортированию.
Шаг 2. Импортирование в проект.
from fuzzywuzzy import fuzz
from fuzzywuzzy import processФункционал
1. Самое обычное сравнение:
a = fuzz.ratio('Привет мир', 'Привет мир')
print(a)
#Выводит в консоль: 100Если мы изменим пару символов, то на выходе получим другое число.
a = fuzz.ratio('Привет мир', 'Привт кир')
print(a)
#Выводит в консоль: 84
2. Частичное сравнение
Данный вид сравнения во всей второй строке ищет совпадение с начальной, например:
a = fuzz.partial_ratio('Привет мир', 'Привет мир!')
print(a)
#Выводит в консоль: 100Или
a = fuzz.partial_ratio('Привет мир', 'Люблю колбасу, Привет мир')
print(a)
#Выводит в консоль: 100Но следует помнить про регистр, так как
a = fuzz.partial_ratio('Привет мир', 'Люблю колбасу, привет мир')
print(a)
#Выводит в консоль: 90
3. Сравнение по токену
1) Token Sort Ratio
Слова сравниваются друг с другом, независимо от регистра или порядка
a = fuzz.token_sort_ratio('Привет наш мир', 'мир наш Привет')
print(a)
#Выводит в консоль: 100a = fuzz.token_sort_ratio('Привет наш мир', 'мир наш любимый Привет')
print(a)
#Выводит в консоль: 78a = fuzz.token_sort_ratio('1 2 Привет наш мир', '1 мир наш 2 ПриВЕт')
print(a)
#Выводит в консоль: 100
2) Token Set Ratio
Это сравнение, в отличие от прошлого, приравнивает строки, если их отличие заключается в повторении слов.
a = fuzz.token_set_ratio('Привет наш мир', 'мир мир наш наш наш ПриВЕт')
print(a)
#Выводит в консоль: 100
4. Продвинутое обычное сравнение
Во многих случаях более целесообразно использовать именно WRatio, так как оно учитывает регистр букв и знаки препинания (не делящие строку)
a = fuzz.WRatio('Привет наш мир', '!ПриВЕт наш мир!')
print(a)
#Выводит в консоль: 100a = fuzz.WRatio('Привет наш мир', '!ПриВЕт, наш мир!')
print(a)
#Выводит в консоль: 97
5. Работа со списком
Для сравнения строки со строками из списка используется модуль process
city = ["Москва", "Санкт-Петербург", "Саратов", "Краснодар", "Воронеж", "Омск", "Екатеринбург", "Орск", "Красногорск", "Красноярск", "Самара"]
a = process.extract("Саратов", city, limit=2)
# Параметр limit по умолчанию имеет значение 5
print(a)
#Выводит в консоль: [('Саратов', 100), ('Самара', 62)]Если необходим только первый в списке, то лучше использовать extractOne
city = ["Москва", "Санкт-Петербург", "Саратов", "Краснодар", "Воронеж", "Омск", "Екатеринбург", "Орск", "Красногорск", "Красноярск", "Самара"]
a = process.extractOne("Краногрск", city)
print(a)
#Выводит в консоль: ('Красногорск', 90)Применение
Как и где применять всё вышеизложенное решать вам, но вот пример из моей курсовой работы:
#открытие файла на рабочем столе
try:
files = os.listdir('C:\Users\hartp\Desktop\')
filestart = process.extractOne(namerec, files)
if filestart[1] >= 80:
os.startfile('C:\Users\hartp\Desktop\' + filestart[0])
else:
speak('Файл не найден')
except FileNotFoundError:
speak('Файл не найден')
Давайте пробежимся по коду и поймём что к чему.
Командой os.listdir мы получаем список всех файлов, которые присутствуют в конце указанного пути (в нашем случае на рабочий стол).
files = os.listdir('C:\Users\hartp\Desktop\')
print(files)
#Выводит в консоль: 'Visual Studio 2019.lnk', 'Visual Studio Code.lnk', 'WarThunder.lnk', 'WpfApp14', 'Yandex.lnk', 'Автобус.docx', 'Аэрофлот.txt', 'Для курсача.txt' и т.д.Далее идёт сравнение строк списка файлов с именем файла, который назвал пользователь (переменная namerec). Надеюсь, вы обратили внимание, что результатом функции extractOne является кортеж из строки и цифры (индекс сходства)
city = ["Москва", "Санкт-Петербург", "Саратов", "Краснодар", "Воронеж", "Омск", "Екатеринбург", "Орск", "Красногорск", "Красноярск", "Самара"]
a = process.extractOne("Краногрск", city)
print(a)
#Выводит в консоль: ('Красногорск', 90).
Исходя из этого, делаем проверку индекса сходства filestart[1] >= 80 ([1], так как в кортеже нумерация с 0, как в массиве) и, если условие верно, то запускаем функцией os.startfile файл с названием filestart[0]. Иначе, если индекс сходства меньше 80 или вылетает ошибка, что файл не найден — сообщаем это пользователю через функцию speak.
Все дороги ведут к матану
Расстояние Левенштейна (редакционное расстояние, дистанция редактирования) — метрика, измеряющая разность между двумя последовательностями символов.
У нас есть две строки S1 размером i и S2 размером j
S1=vrhk
S2=rhgr
Существует только 3 операции:
- Замена: r → v
- Удаление: -r
- Подстановка: rVhgr
Теперь создадим табличку для сравнения этих двух строк:

Откуда в таблице появились 0 и 1? Для превращения пустого символа в пустой символ нам никаких операций проводить не нужно (пишем в таблицу — «0»), а для превращения символа r в пустую строку, необходимо удалить r (одно действие, пишем в таблицу — «1»). С символом v аналогичная ситуация.
Для перехода rh в пустой символ необходимо сначала удалить h, а потом r (используется две операции), следовательно, таблица примет вид:
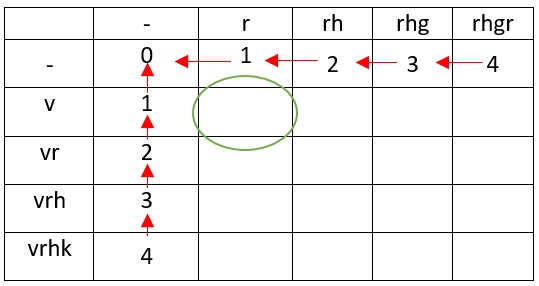
Теперь рассмотрим ситуацию превращения v в r (отмечена зелёным кругом на таблице). Существует несколько путей, но мы выбираем наименьший — превращение пустого символа в v. В ячейку заносим 1. Как так получилось? Мы представляем r как строку, которую нужно превратить в строку v. Перед r существует пустой символ, который мы заменяем на v, получая строку rv. Так как мы проверяем символы справа налево, то v совпадает с v.

Пришло время рассмотреть превращение v в rh
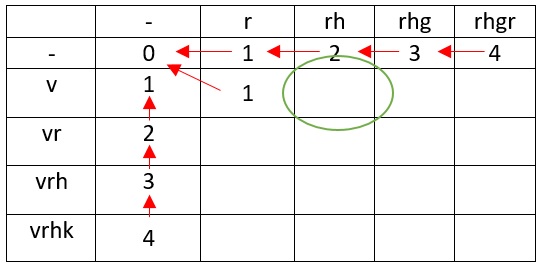
Самый удачный вариант — v мы заменяем на h и всё сводится к задаче превращения r в пустую строку.

Результат заносим в таблицу.
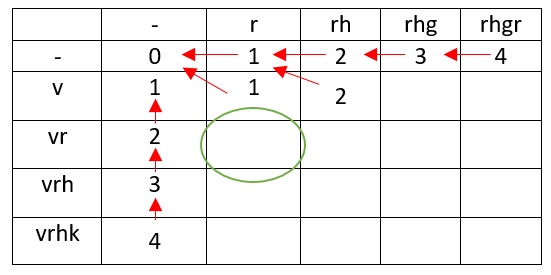
В сравнении vr с r нужно учесть, что последние символы совпадают, а это значит, что задача просто сводится до более простой, без изменения расстояния Левенштейна.

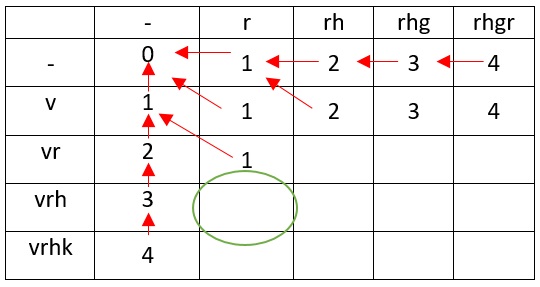
При преобразовании vrh в r достаточно удаления h и эта задача сводится к предыдущей (сравнение vr с r), следовательно расстояние будет равно 2


Как и в случае сравнения vr с r у нас совпадают окончание строк vrh и rh, следовательно, расстояние не изменится.
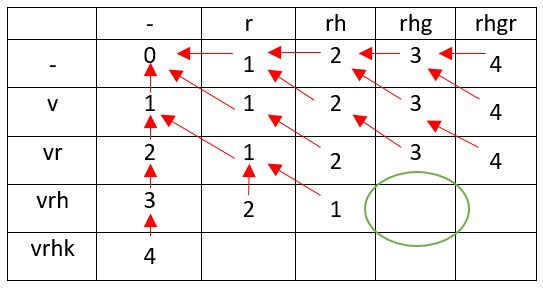
Заметьте, что vrh и rhg идентичны с нашим предыдущим преобразованием, но с отличием в одну букву, которую просто необходимо убрать, именно из-за этого наше расстояние увеличивается на единицу (обратите внимание на стрелку).
Опираясь на все примеры, описанные выше, мы получаем кратчайшое редакционное расстояние (расстояние Левенштейна) между двумя строками — vrhk и rhgr.
Благодарю всех за внимание! Надеюсь данная статья кому-нибудь окажется полезной.
Специально для сайта ITWORLD.UZ. Новость взята с сайта Хабр