
В статье вы узнаете, как разворачивать модели машинного обучения и составлять прогнозы при помощи любого языка программирования, который вам нравится. Конечно, за основу вы можете взять Python или же генерировать прогнозы напрямую внутри Android-приложения на Java или Kotlin. Также вы можете использовать свою модель в веб-приложении. Вариантов бесконечное множество. Чтобы было проще объяснить, я выбрал Postman.
Оговорюсь, что я не буду объяснять, как выложить модель на “живой” сервер. Вариантов слишком много, а также это скорее тема для отдельного поста. Модель будет работать на вашей локальной машине, так что доступа из другой сети вы не получите. Если нужно, загуглите, как развернуть модель на AWS.
Я создал вот такую структуру директорий:
ML-Deploy
- model / Train.py
- app.py
Теперь, если у вас Python установлен через Anaconda, то, скорее всего, у вас есть все предустановленные библиотеки, может быть, без Flask. Чтобы установить Flask выполним следующее:
pip install Flask pip install Flask-RESTful
Хорошо прошло? Отлично. Погружаемся глубже в интересные процессы.
Создание стандартного скрипта прогнозирования
Пройдитесь по структуре директории, откройте файл model/Train.py. Цель — загрузить в датасет Iris и применить простое дерево решения для обучения модели. Я возьму библиотеку joblib, чтобы сохранить модель в момент окончания обучения. Также я собираюсь вернуть отчет с оценкой точности пользователю.
Тут ничего сложного. Сосредоточимся на теме статьи — развёртывании модели. Привожу для вас весь скрипт:
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.externals import joblib
def train_model():
iris_df = datasets.load_iris()
x = iris_df.data
y = iris_df.target
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
dt = DecisionTreeClassifier().fit(X_train, y_train)
preds = dt.predict(X_test)
accuracy = accuracy_score(y_test, preds)
joblib.dump(dt, 'iris-model.model')
print('Model Training Finished.ntAccuracy obtained: {}'.format(accuracy))Развёртывание
Теперь мы готовы открыть файл app.py и прописать импорты. Вам будет нужен модуль os, а также пара вещей из Flask и Flask-RESTful. Еще: скрипт обучения модели, созданный 10 секунд назад и joblib для загрузки в обучающуюся модель:
import os
from flask import Flask, jsonify, request
from flask_restful import Api, Resource
from model.Train import train_model
from sklearn.externals import joblibА теперь следует создать инстанс Flask и Api из Flask-RESTful. Это очень просто:
app = Flask(__name__) api = Api(app)
Далее проверим, прошла ли модель обучение. В файле Train.py мы прописали, что модель будет сохраняться в файле iris-model.model. Следовательно, если такого файла не существует, то сначала модель надо обучить. После одного прогона вы сможете загрузить ее при помощи joblib:
if not os.path.isfile('iris-model.model'):
train_model()
model = joblib.load('iris-model.model')Теперь давайте пропишем класс для прогнозирования. Flask-RESTful использует определенное соглашение о кодировании, так что ваш класс должен наследовать модуль Flask-RESTful Resource. Внутри класса вы можете прописать get(), post() или любой другой метод для обработки данных.
У нас будет post(), так что данные не будут передаваться напрямую через URL. Нужно получить атрибуты из данных, введенных пользователем. Прогнозирование генерируется на основе значения атрибута, введённого пользователем. Теперь можно вызвать функцию .predict() загруженной модели. Так как целевая переменная этого датасета имеет вид (0, 1, 2) вместо (‘Iris-setosa’, ‘Iris-versicolor’, ‘Iris-virginica’), вам понадобится учесть это ветвлением, как показано в коде ниже. Наконец, можете возвращать представление прогноза в JSON:
class MakePrediction(Resource):
@staticmethod
def post():
posted_data = request.get_json()
sepal_length = posted_data['sepal_length']
sepal_width = posted_data['sepal_width']
petal_length = posted_data['petal_length']
petal_width = posted_data['petal_width']
prediction = model.predict([[sepal_length, sepal_width, petal_length, petal_width]])[0]
if prediction == 0:
predicted_class = 'Iris-setosa'
elif prediction == 1:
predicted_class = 'Iris-versicolor'
else:
predicted_class = 'Iris-virginica'
return jsonify({
'Prediction': predicted_class
})Мы почти закончили, пристегните ремни! Нужно прописать маршрут, часть адреса которого нужна для контроля запросов:
api.add_resource(MakePrediction, '/predict')
И последняя вещь — сообщить Python о запуске приложения в режиме отладки:
if __name__ == '__main__':
app.run(debug=True)
Настал момент истины. Можно запустить модель и сгенерировать прогноз при помощи Postman или какого-то другого инструмента. И на случай, если вы пропустите что-то, есть файл app.py:
import os
from flask import Flask, jsonify, request
from flask_restful import Api, Resource
from model.Train import train_model
from sklearn.externals import joblib
app = Flask(__name__)
api = Api(app)
if not os.path.isfile('iris-model.model'):
train_model()
model = joblib.load('iris-model.model')
class MakePrediction(Resource):
@staticmethod
def post():
posted_data = request.get_json()
sepal_length = posted_data['sepal_length']
sepal_width = posted_data['sepal_width']
petal_length = posted_data['petal_length']
petal_width = posted_data['petal_width']
prediction = model.predict([[sepal_length, sepal_width, petal_length, petal_width]])[0]
if prediction == 0:
predicted_class = 'Iris-setosa'
elif prediction == 1:
predicted_class = 'Iris-versicolor'
else:
predicted_class = 'Iris-virginica'
return jsonify({
'Prediction': predicted_class
})
api.add_resource(MakePrediction, '/predict')
if __name__ == '__main__':
app.run(debug=True)
Отлично. Пройдите в директорию с app.py, запустите терминал и выполните эту команду:
python app.py
После второго или третьего раза вы получите выходные данные и убедитесь, что приложение запущено на локальной машине.
Сейчас я открою Postman и сделаю следующее:
- Поменяю метод на
POST. - Напишу
localhost:5000/predictв качествеURL. - На вкладке Body выберу
JSON. - Напишу немного JSON для прогнозирования.
Теперь можно нажать Send:
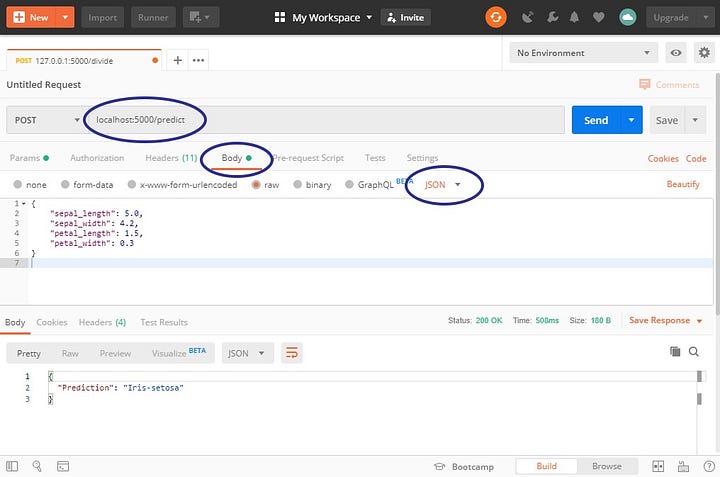
Практически мгновенно вы получите прогноз от своей модели.
Заключение
Надеюсь, вы разобрались с моей статьёй. У вас должно получиться, даже если вы просто скопируете и вставите все, при условии наличия всех необходимых библиотек.
Я рекомендую применить эти новые знания на ваших датасетах и бизнес-задачах. Набить руку получиться, если вы пишете приложение на каком-то другом языке, не на Python. Python используйте только для задач, связанных с данными и машинным обучением. Спасибо, что прочли. Берегите себя!
Специально для сайта ITWORLD.UZ. Новость взята с сайта NOP::Nuances of programming