
Введение
SQL (язык структурированных запросов) — язык программирования, используемый для запроса и управления данными в реляционных базах данных. Реляционные базы данных состоят из наборов двумерных таблиц. Каждая из этих таблиц содержит фиксированное количество столбцов и строк.
Наряду с Python и R, SQL считается одним из важнейших навыков в науке о данных (рисунок 1). Некоторые причины популярности SQL:
- Ежедневно генерируется около 2,5*1018 байт данных. Для хранения таких больших объемов необходимо использовать базы данных.
- В настоящее время компании уделяют все больше внимания ценности данных. Например, данные можно использовать для анализа и решения бизнес-задач, прогнозирования рыночных тенденций и понимания потребностей клиентов.
Одним из основных преимуществ использования SQL является возможность получения прямого доступа при выполнении операций с данными (без необходимости предварительного копирования), что значительно ускоряет работу.
 Рисунок 1: Наиболее востребованные для работы с данными навыки, июнь 2019 г. [1]
Рисунок 1: Наиболее востребованные для работы с данными навыки, июнь 2019 г. [1]Существует множество различных серверов баз данных SQL: SQLite, MySQL, Postgres, Oracle и Microsoft SQL Server.
В этой статье мы узнаем, как начать работу с SQL с помощью Google BigQuery и Kaggle. С точки зрения науки о данных, SQL может использоваться как для предварительной обработки, так и в целях машинного обучения. Весь код, используемый в этом руководстве, написан на Python.
Согласно документации BigQuery:
BigQuery — это корпоративное хранилище данных, которое решает проблемы, обеспечивая сверхбыстрые SQL-запросы с использованием вычислительной мощности инфраструктуры Google.
Начало работы
При работе с ядрами Kaggle (онлайн-версия Jupyter Notebooks, встроенная в системы Kaggle) доступна опция активации Google BigQuery (рисунок 2). Фактически Kaggle предоставляет бесплатный сервис BigQuery объемом до 5 терабайт в месяц на одного пользователя (при окончании месячного резерва необходимо подождать до следующего месяца).
Чтобы использовать BigQuery ML, нужно создать бесплатную учетную запись Google Cloud Platform и экземпляр проекта в сервисе Google. Здесь можно найти руководство о том, как начать работу.
 Рисунок 2: Активация BigQuery в ядрах Kaggle
Рисунок 2: Активация BigQuery в ядрах KaggleУ проектов BigQuery на Google Account Platform есть идентификатор. Используем его, чтобы соединить ядро Kaggle с BigQuery. Выполним несколько строк кода:
from google.cloud import bigquery
import matplotlib.pyplot as plt
import numpy as np
# Добавление ID проекта из Google Cloud Platform
PROJECT_ID = 'addyourprojectidhere'
client = bigquery.Client(project=PROJECT_ID, location="US")
dataset = client.create_dataset('tds_tutorial', exists_ok=True)
В этой демонстрации используется набор данных OpenAQ (рисунок 3). Этот набор содержит информацию о качестве воздуха со всего мира.
# Создание ссылки на таблицу
table = client.get_table("bigquery-public-data.openaq.global_air_quality")
# Просмотр первых пяти строк из набора данных
client.list_rows(table, max_results=5).to_dataframe()
 Рисунок 3: Набор данных OpenAQ
Рисунок 3: Набор данных OpenAQПредварительная обработка данных
Рассмотрим основные SQL-запросы для предварительной обработки данных.
Для начала выясним количество городов страны, в которых проводились измерения качества воздуха. Для этого выбираем столбец Country и выполняем подсчет всех местоположений в столбце location. Затем группируем результаты по странам и располагаем их в порядке убывания.
# Проверка количества станций измерения в каждой стране
query = """SELECT country, COUNT(location) AS number_of_locations
FROM `bigquery-public-data.openaq.global_air_quality`
GROUP BY country
ORDER by number_of_locations DESC"""
query_job = client.query(query)
query_job.to_dataframe().head(10)
Первые десять результатов показаны на рисунке 4.
 Рисунок 4: Количество станций измерения в каждой стране
Рисунок 4: Количество станций измерения в каждой странеТеперь можно рассмотреть некоторые статистические характеристики столбцов Value (значение) и Averaged Over In Hours (среднее значение по часам), взяв µg/m³ в качестве единицы. Таким образом, можно быстро проверить наличие каких-либо аномалий.
Столбец Value представляет последнее измеренное значение загрязняющих веществ, а в столбце Averaged Over In Hours указано количество часов, за которое значение было приведено к среднему показателю.
# Сводная статистика
query = """SELECT value,averaged_over_in_hours
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE unit = 'µg/m³'
"""
query_job = client.query(query)
query_job.to_dataframe().describe()
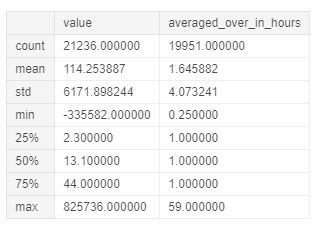 Рисунок 5. Статистическая сводка по столбцам Value и Averaged Over In Hours
Рисунок 5. Статистическая сводка по столбцам Value и Averaged Over In HoursВ завершение краткого анализа рассчитаем среднее значение концентрации озона в каждой из стран и создадим гистограмму с помощью Matplotlib для получения результатов (рисунок 6).
# Расчет среднего значения концентрации озонового газа в каждой стране
query = """
SELECT
country,
avg(value) as avg_value
FROM
`bigquery-public-data.openaq.global_air_quality`
WHERE
pollutant = 'o3'
AND country != 'NL'
AND country != 'DK'
AND country != 'LT'
AND country != 'LU'
AND unit = 'µg/m³'
GROUP BY country
ORDER BY avg_value ASC
"""
query_job = client.query(query)
query_df = query_job.to_dataframe()
plt.subplots(figsize=(12,7))
y_pos = np.arange(len(query_df.country))
plt.bar(y_pos, query_df.avg_value, align='center', alpha=0.7)
plt.xticks(y_pos, query_df.country.values)
plt.ylabel('NO2 values in µg/m³', fontsize=16)
plt.xticks(rotation= 60,fontsize=16)
plt.xlabel('Country', fontsize=16)
plt.title('Ozone gas Average in different countries', fontsize=20)
plt.show()
 Рисунок 6: Среднее значение концентрации озона в каждой стране
Рисунок 6: Среднее значение концентрации озона в каждой странеМашинное обучение
Google Cloud предоставляет еще один сервис под названием BigQuery ML, предназначенный для выполнения задач машинного обучения напрямую с использованием SQL-запросов.
Согласно документации BigQuery ML:
С помощью BigQuery ML можно создавать и выполнять модели машинного обучения с использованием стандартных SQL-запросов. BigQuery ML повышает доступность машинного обучения, позволяя специалистам по SQL создавать модели с использованием существующих инструментов и навыков в SQL. BigQuery ML увеличивает скорость разработки, устраняя необходимость перемещения данных.
Использование BigQuery ML предоставляет такие преимущества, как отсутствие необходимости читать данные в локальной памяти и использование нескольких языков, а также возможность работы модели сразу после обучения. Некоторые модели машинного обучения, поддерживаемые BigQuery ML:
- Линейная регрессия.
- Логистическая регрессия.
- Метод K-средних.
- Импорт предварительно обученных моделей TensorFlow.
Для начала нужно импортировать все необходимые зависимости. В данном случае мы также интегрируем magic-команду BigQuery в Notebook для улучшения читабельности кода.
from google.cloud.bigquery import magics from kaggle.gcp import KaggleKernelCredentials magics.context.credentials = KaggleKernelCredentials() magics.context.project = PROJECT_ID %load_ext google.cloud.bigquery
Теперь можно перейти к созданию модели. В этом примере используется логистическая регрессия (только на первых 800 примерах для уменьшения потребления памяти), чтобы предсказать название страны с учетом ее широты, долготы и уровня загрязнения.
%%bigquery CREATE MODEL IF NOT EXISTS `tds_tutorial.Model` OPTIONS(model_type='logistic_reg') AS SELECT country AS label, latitude, longitude, value FROM `bigquery-public-data.openaq.global_air_quality` LIMIT 800;
После обучения модели можно просмотреть сводку обучения с помощью следующих команд (рисунок 7).
%%bigquery SELECT * FROM ML.TRAINING_INFO(MODEL `tds_tutorial.Model`) ORDER BY iteration
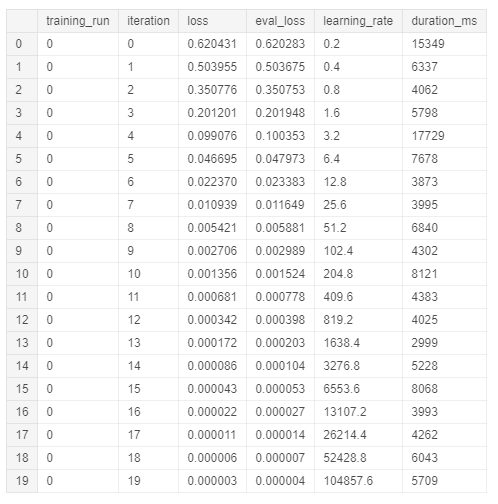 Рисунок 7: Сводка по обучению логистической регрессии
Рисунок 7: Сводка по обучению логистической регрессииТеперь можно перейти к оценке точности производительности модели, используя функцию BigQuery ML.EVALUETE (рисунок 8).
%%bigquery SELECT * FROM ML.EVALUATE(MODEL `tds_tutorial.Model`, ( SELECT country AS label, latitude, longitude, value FROM `bigquery-public-data.openaq.global_air_quality` LIMIT 800))
 Рисунок 8: Оценка модели BigQuery ML
Рисунок 8: Оценка модели BigQuery MLСпециально для сайта ITWORLD.UZ. Новость взята с сайта NOP::Nuances of programming