О дизайн-решениях в работе с MongoDB, которые пригодятся каждому фуллстек-разработчику, а также о том, как лучше организовать отношения: один к одному, один ко многим, многие ко многим.

С момента зарождения вычислительной техники объем доступных данных постоянно растет. Вместе с тем растут и потребности в эффективных технологиях хранения, обработки и анализа информации.
В последние годы набирают популярность NoSQL базы данных (англ. Not only SQL, не только SQL). Одна из популярнейших среди них – MongoDB.
NoSQL-модель отличается от классической реляционной модели. Об этом важно помнить, выстраивая архитектуру программного обеспечения. Неправильный выбор дизайна плохо скажется на масштабируемости и производительности.
Поэтому сегодня мы разберем пару практических шаблонов проектирования MongoDB-приложений, которые пригодятся каждому MERN/MEAN-разработчику:
- Полиморфная схема.
- Агрегационнная модель данных.
Предполагается, что вы имеете базовые навыки работы с MongoDB, а также имеете понимание реляционного моделирования, которое будет приведено в некоторых местах в качестве альтернативного решения.
Большая схема всего
MongoDB часто представляют как базу данных, у которой нет схемы. Но это неверно: схема есть, но она динамична. Ее называют полиморфной, так как она может трансформироваться даже на документах одной и той же коллекции. Это позволяет хранить вместе разные наборы информации, что в условиях бурного развития неструктурированных больших данных является мощным конкурентным преимуществом.
Наследование и полиморфизм
Когда речь заходит об объектно-ориентированном программировании (ООП) и наследовании, полиморфные возможности MongoDB становятся особенно важными и удобными. Благодаря им можно сериализовать экземпляры разных классов одной иерархии (родитель-потомок) в одну коллекцию, а затем десериализовать их обратно в объекты.
В реляционных базах данных такой прием не удалось бы провести так просто, ведь таблицы имеют фиксированные схемы.
Возьмем для примера торговую систему. В ней есть базовый класс ценных бумаг (Security) и конкретные классы акций (Stock), активов (Equity) и опционов (Option).
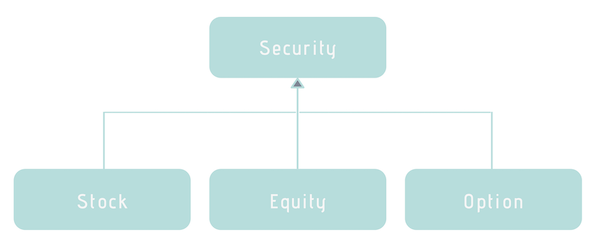
Структура классов торговой системы
В MongoDB это решается очень просто. Мы храним производные типы в одной коллекции Security и добавляем дискриминатор (_t) к каждому документу.
В реляционной базе есть несколько вариантов решения этой задачи:
- Единая таблица с объединением полей для акций, активов и опционов. При этом часть ячеек останется пустой (sparsely populated schema).
- Три таблицы, по одной для каждого конкретного класса. Это приводит к избыточности (redundancy), так как базовая информация повторяется в каждой таблице, а также к сложным запросам для извлечения всех видов ценных бумаг.
- Одна таблица для общих данных всех типов ценных бумаг и три отдельных таблицы для акций, активов и опционов. Они будут ссылаться на первую таблицу по идентификатору и содержать только уникальные атрибуты. Такой подход устраняет избыточность, но запросы по всем классам остаются сложными.
Очевидно, что с полиморфными коллекциями MongoDB все решается быстрее и проще.
Изменение схемы
Единственная постоянная вещь в жизни – это изменение.
Для схемы базы данных это утверждение так же верно, как и для всего остального. Необходимость изменить структуру традиционной реляционной базы может стать головной болью для разработчика. Нормализованная табличная схема великолепно устраняет избыточность данных. Но при небольшом изменении одной таблицы сторонние эффекты могут проявиться самым неожиданным образом.
Обычно это происходит так:
- Приложение останавливается и создается резервная копия базы.
- Запускаются сложные сценарии миграции для поддержки новой схемы.
- Код перерабатывается, чтобы взаимодействовать с этой схемой.
- После внесения всех изменений приложение перезапускается.
При непрерывном развертывании (CD, Continuous Delivery), самой трудоемкой задачей, требующей длительного простоя, оказывается миграция базы. Некоторые команды ALTER на больших таблицах могут выполняться несколько дней!
Однако MongoDB из коробки поддерживает обратную совместимость. Разработчики учитывают эти изменения в коде на стороне сервера. Как только приложение будет обновлено, чтобы справиться с изменениями базы, мы можем перенести нужную коллекцию в фоновом режиме, не останавливая его. После миграции можно заменить код приложения для окончательного внедрения изменений.
Все изменяется, в том числе и схемы баз данных. В традиционных табличных базах эти изменения могут быть очень неприятными и даже парализовать работу приложения. MongoDB же отлично с ними справляется.
Ничто не высечено в камне, в том числе схемы баз данных
Встраивать или не встраивать: вот в чем вопрос!
Возможно, вы знакомы с классической книгой Эрика Эванса (Eric Evans) Domain Driven Design. В ней описываются агрегатные модели.
Агрегат – это совокупность данных, с которыми мы взаимодействуем как с единым целым. Обычно он имеет более сложную структуру, чем традиционная строка/запись и может содержать вложенные списки, словари или другие составные типы.
Атомарность поддерживается на уровне агрегата, то есть агрегат образует границу ACID-операции (подробнее можно прочитать в руководстве MongoDB). Обработка межагрегатных связей сложнее, чем внутриагрегатных: объединения (joins) не поддерживаются непосредственно в ядре, но управляются из кода приложения или с помощью aggregation framework.
Нет единственно правильного решения в дилемме встраивания связанных объектов. В каждой конкретной ситуации вы должны оценить данные и способы взаимодействия с ними и решить: следует ли вставлять такие объекты друг в друга или лучше завести отдельную коллекцию и ссылаться по идентификатору.
У встраивания есть свои преимущества:
- Производительность чтения. Она связана с природой способа организации дисков компьютера. При поиске конкретной записи машине требуется время (высокая задержка), но как только запись найдена, доступ к любым дополнительным байтам осуществляется очень быстро (высокая пропускная способность). Таким образом, связанная информация может быть получена за один раз.
- Сокращение круговых запросов к базе для получения отдельных коллекций.
Выбор правильного дизайна во многом зависит от типа отношений между связанными сущностями.
1:1 (Один к одному)
Одна запись из сущности A связана ровно с одной записью из сущности B.
Смоделировать такое отношение можно двумя способами:
- Прямое встраивание дочернего объекта в виде поддокумента;
- Размещение дочерних документов в отдельной коллекции и связывание через идентификатор. При этом не применяются никакие ограничения внешнего ключа, так как отношения существуют только в схеме уровня приложения, а не базы.
Выбор способа зависит от того, как приложение получает доступ к данным, и как часто это происходит. Важен и жизненный цикл набора данных. Например, что должно произойти с объектом B, если будет удален объект A?
Золотое Правило #1. Если объектBдолжен быть доступен сам по себе (вне контекста родительского объектаA), то используйте ссылку, иначе встраивайте напрямую.
1:N (Один ко многим)
Отношение между сущностями A и B, при котором одна сторона может иметь одну или несколько связей с другой. Вторая сторона при этом всегда имеет только одну связь.
Смоделировать подобное отношение в базе также можно с помощью прямых вложений или ссылками.
Возможности встраивания при этом серьезно ограничены. Например, не рекомендуется его использовать если поддокумент будет увеличиваться:
- Размер каждого документа не может превышать 16 Мбайт.
- Для растущего документа нужно будет выделять новое пространство, а также обновлять индексы, что влияет на производительность.
В таких ситуациях лучше предпочесть ссылки. Объекты A и B при этом моделируются как автономные коллекции. При этом производительность чтения снижается, так как приходится выполнять второй запрос для получения сведений о сущности B. Чтобы решить эту проблему используйте рациональное индексирование (для оптимизации памяти) и проекции (для снижения пропускной способности).
Другой вариант – использование предварительно агрегированных коллекций, действующих как OLAP-кубы, для упрощения некоторых объединений.
Золотое Правило #2. Массивы не должны расти без привязки. Если на стороне B меньше пары сотен документов, то их можно безопасно встроить. Если их больше пары сотен, то лучше использовать связывание по идентификатору. Если таких документов несколько тысяч, то предпочтительнее использовать ссылку на родителя, а не на потомка. Документ B ссылается на соответствующий документ A.
Золотое Правило #3. Соединение коллекций на уровне приложения является обычной практикой и не должно вас смущать. В этих случаях важно настроить рациональное индексирование.
Факторы, способствующие денормализации документов:
- Обновления больше не будут атомарными.
- Высокое отношение чтения к записи. Поле, которое в основном читается и редко обновляется, является хорошим кандидатом для денормализации.
N:M (Многие ко многим)
В таком отношение обе стороны (A и B) могут иметь одну или несколько связей с другой стороной.
В реляционных базах такие случаи моделируются с помощью таблицы соединений, но в MongoDB мы можем использовать двунаправленное встраивание. Мы запрашиваем A для поиска встроенных ссылок на B-объекты, а затем запрашиваем B с оператором $in, чтобы найти эти ссылки. И наоборот.
Здесь сложность возникает из-за установления равномерного баланса между A и B, поскольку порог в 16 МБ также может быть нарушен. В сложных случаях рекомендуется использовать одностороннее встраивание.

Использование встраивания или ссылок в MongoDB
MongoDB дает возможность проектировать схему базы в соответствии с потребностями приложения для получения максимальной отдачи. Эта гибкость дает огромные возможности, но при неправильном использовании может привести к ухудшению производительности.
У нас есть еще пара статей, в которых участвует mongoDB:
Источники
Специально для сайта ITWORLD.UZ. Новость взята с сайта Библиотека программиста