
На мой взгляд, главная составляющая любого программирования – это читабельность кода, будь то написанный вами или кем-то другим. Читабельность складывается из множества факторов, начиная от синтаксиса языка программирования, имен переменных, комментариев и заканчивая отступами. Но мне бы хотелось поговорить о последнем пункте – об отступах.
Речь пойдет не о размере отступов или выборе между табуляцией и пробелами, и даже не о необходимости использования их в языках по типу Python. Многим людям почему-то нравится использовать максимальную длину строки в коде (~ 80-120 знаков). В предложенной мной концепции длина строки ничем не ограничивается, и иногда даже придется прибегнуть к горизонтальной прокрутке. Не пугайтесь, это касается не всего кода, а лишь выборочных строк.
Четыре примера совершенствования кода с использованием отступов
Первый пример
Взгляните на этот код:
const columns = [
{ name: 'id', index: 'id', width: 55 },
{ name: 'invdate', index: 'invdate', width: 90 },
{ name: 'name', index: 'name asc, invdate', width: 100 },
{ name: 'amount', index: 'amount', width: 80, align: "right" },
{ name: 'tax', index: 'tax', width: 80, align: "right" },
{ name: 'total', index: 'total', width: 80, align: "right" },
{ name: 'note', index: 'note', width: 150, sortable: false }
];
Читабельность у него так себе. А вот так код станет более осмысленным:
const columns = [
{
name: 'id',
index: 'id',
width: 55
},
{
name: 'invdate',
index: 'invdate',
width: 90
},
{
name: 'name',
index: 'name asc, invdate',
width: 100
},
{
name: 'amount',
index: 'amount',
width: 80,
align: "right"
},
{
name: 'tax',
index: 'tax',
width: 80,
align: "right"
},
{
name: 'total',
index: 'total',
width: 80,
align: "right"
},
{
name: 'note',
index: 'note',
width: 150,
sortable: false
}
];
Таким образом, ваши семь строк растянулись на целых 40. Но здесь у нас всего лишь 3-4 свойства на объект. Если же свойств будет 8, то строчек станет 70.
Моя идея сводится к тому, чтобы использовать вот такие конструкции (я называю такой код «с разбивкой на столбцы»):
const columns = [
{ name: 'id' , index: 'id' , width: 55 },
{ name: 'invdate', index: 'invdate' , width: 90 },
{ name: 'name' , index: 'name asc, invdate', width: 100 },
{ name: 'amount' , index: 'amount' , width: 80 , align: "right" },
{ name: 'tax' , index: 'tax' , width: 80 , align: "right" },
{ name: 'total' , index: 'total' , width: 80 , align: "right" },
{ name: 'note' , index: 'note' , width: 150, sortable: false }
];
Второй пример
Им можно выделять не только литералы объекта. Такая конструкция подойдет для любой части кода, состоящего из группы одинаковых строк. А сам процесс можно в разы ускорить: копируете первую строку, вставляете ее, а затем построчно дописываете нужные значения.
Кстати, такой пример пригодится и для import в JS. Сравните две версии кода:
import { Schemas } from 'vs/base/common/network';
import { IProcessEnvironment , isMacintosh } from 'vs/base/common/platform';
import { TPromise } from 'vs/base/common/winjs.base';
import { whenDeleted } from 'vs/base/node/pfs';
import { IChannel } from 'vs/base/parts/ipc/common/ipc';
import { IConfigurationService } from 'vs/platform/configuration/common/configuration';
import { ParsedArgs , IEnvironmentService } from 'vs/platform/environment/common/environment';
import { createDecorator } from 'vs/platform/instantiation/common/instantiation';
import { ILogService } from 'vs/platform/log/common/log';
import { IURLService } from 'vs/platform/url/common/url';
import { OpenContext , IWindowSettings } from 'vs/platform/windows/common/windows';
import { IWindowsMainService , ICodeWindow } from 'vs/platform/windows/electron-main/windows';
import { IWorkspacesMainService } from 'vs/platform/workspaces/common/workspaces';
Тринадцать импортов располагаются в алфавитном порядке и упорядочены по пути объектов. Все они находятся в папке vs : пять из них расположены в vs/base , а восемь – в vs/platform.
Вы не сможете быстро найти эту информацию, не прочитав содержимое каждой строки. И столь въедливое вычитывание начинает раздражать уже очень быстро. Конечно же, вам не нужна статистика о том, как одни ваши файлы импортируют другие. Но иногда наступает момент, когда вам нужно залезть в код и проверить, что вы делаете импорт правильного файла, или что данный файл уже был импортирован.
А теперь взгляните, как можно написать тот же самый код с разбивкой по столбцам:
import { Schemas } from 'vs/base/common/network' ;
import { IProcessEnvironment , isMacintosh } from 'vs/base/common/platform' ;
import { TPromise } from 'vs/base/common/winjs.base' ;
import { whenDeleted } from 'vs/base/node/pfs' ;
import { IChannel } from 'vs/base/parts/ipc/common/ipc' ;
import { IConfigurationService } from 'vs/platform/configuration/common/configuration' ;
import { ParsedArgs , IEnvironmentService } from 'vs/platform/environment/common/environment' ;
import { createDecorator } from 'vs/platform/instantiation/common/instantiation' ;
import { ILogService } from 'vs/platform/log/common/log' ;
import { IURLService } from 'vs/platform/url/common/url' ;
import { OpenContext , IWindowSettings } from 'vs/platform/windows/common/windows' ;
import { IWindowsMainService , ICodeWindow } from 'vs/platform/windows/electron-main/windows' ;
import { IWorkspacesMainService } from 'vs/platform/workspaces/common/workspaces' ;
Разве не лучше?
Третий пример
В данном примере у нас есть объявление методов из компилятора TypeScript compiler:
/**
* Filters an array by a predicate function. Returns the same array instance if the predicate is
* true for all elements, otherwise returns a new array instance containing the filtered subset.
*/
export function filter<T, U extends T>(array: T[], f: (x: T) => x is U): U[];
export function filter<T>(array: T[], f: (x: T) => boolean): T[];
export function filter<T, U extends T>(array: ReadonlyArray<T>, f: (x: T) => x is U): ReadonlyArray<U>;
export function filter<T, U extends T>(array: ReadonlyArray<T>, f: (x: T) => boolean): ReadonlyArray<T>;
export function filter<T>(array: T[], f: (x: T) => boolean): T[] {
if (array) {
const len = array.length;
let i = 0;
// ...
/**
* Filters an array by a predicate function. Returns the same array instance if the predicate is
* true for all elements, otherwise returns a new array instance containing the filtered subset.
*/
export function filter<T, U extends T>(array: T[], f: (x: T) => x is U ): U[];
export function filter<T >(array: T[], f: (x: T) => boolean): T[];
export function filter<T, U extends T>(array: ReadonlyArray<T> , f: (x: T) => x is U ): ReadonlyArray<U>;
export function filter<T, U extends T>(array: ReadonlyArray<T> , f: (x: T) => boolean): ReadonlyArray<T>;
export function filter<T >(array: T[], f: (x: T) => boolean): T[] {
if (array) {
const len = array.length;
let i = 0;
// ...
Отступы тут проставлялись автоматически, через расширение Smart Column Indenter от Visual Studio Code.
Теперь разница содержимого строк выглядит более наглядно. Так вы сможете «прочесть» все пять строк одновременно, приложив минимум усилий. А добавление параметра в эти строки реализовать проще простого: один раз прописываете значение и используете многострочный курсор, который есть почти во всех редакторах кода.
Четвертый пример
Наш последний пример. Тут идет сравнение оригинала и кода с отступами:
function Node(this: Node, kind: SyntaxKind, pos: number, end: number) {
this.pos = pos;
this.end = end;
this.kind = kind;
this.id = 0;
this.flags = NodeFlags.None;
this.modifierFlagsCache = ModifierFlags.None;
this.transformFlags = TransformFlags.None;
this.parent = undefined;
this.original = undefined;
}
function Node(this: Node, kind: SyntaxKind, pos: number, end: number) {
this.pos = pos ;
this.end = end ;
this.kind = kind ;
this.id = 0 ;
this.flags = NodeFlags.None ;
this.modifierFlagsCache = ModifierFlags.None ;
this.transformFlags = TransformFlags.None;
this.parent = undefined ;
this.original = undefined ;
}
Плюсы:
- Код выглядит чище.
- Улучшается читабельность.
- Можно сократить количество строк в коде.
Минусы:
- Опция авто-форматирования в редакторах кода может конфликтовать с разметкой.
- Иногда при добавлении одной строки в блок приходится менять все остальные строки.
- Возрастают временные затраты на написание кода.
Какие инструменты могут помочь?
Какое-то время я проставлял отступы вручную. Скука смертная, но стоит начать и остановиться почти невозможно. Вы смотрите на код, видите одинаковые строки, которые так и просят разбить их на колонки для лучшей читаемости, и все – пройти мимо уже невозможно. Настоящая зависимость.
Я привык работать в Visual Studio и Visual Studio Code, поэтому в свое время старался найти плагин или расширение, которое бы смогло бы автоматизировать весь процесс. Ничего не нашлось. Так что в ноябре 2017 года я начал писать свое расширение для Visual Studio Code и назвал его Smart Column Indenter.
В том же месяце вышла первая доступная версия. Посмотрите, как она работает:
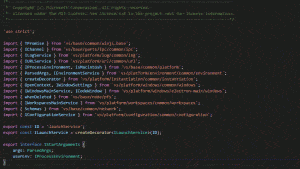
Конечно же, это расширение нужно еще доработать. В данный момент поддерживаются только *.ts, *.js и *.json . Думаю, что в XML и HTML файлах оно бы тоже пригодилось – можно было бы разбивать на столбцы одинаковые атрибуты повторяющихся тегов, или, наоборот, разные теги, повторяющиеся в группе строк.
Для разбивки на столбцы необходимо выбрать участок кода, затем происходит выполнение алгоритма в три этапа:
1. Лексический анализ (или токенизация кода). Для зависимых элементов я установил пакет npm на TypeScript, а благодаря Compiler API не приходится делать лишних телодвижений.
2. Выполнение алгоритма наибольшей общей подпоследовательности (LCS) – каждая строка кода передается в виде последовательности токенов. Это самый трудный этап. Многие источники в интернете показывают работу LCS на примере только двух последовательностей во входных значениях. Такая задача легко решаема динамическим программированием. А поскольку разбивку по столбцам мы будем делать для большего количества строк в коде, то возникает проблема нахождения самой длинной общей последовательности (LCS) множества строк. Это НП-трудная проблема. Ввиду ее распространенности пришлось создать отдельный npm-пакет (multiple-lcs) с базовой реализацией такого выполнения. Нельзя сказать, что это идеальное решение, но, по крайней мере, оно работоспособно.
3. Перезапись кода в столбцы токенов, которые появятся в LCS. Каждый токен в LCS располагается в новом столбце.
Для некоторых типов токенов (например, имена строк и переменных) вместо содержимого LCS-алгоритма используется имя типа. В результате мы получаем бóльшую подпоследовательность.
Всю логику я убрал в отдельный npm-пакет (smart-column-indenter). Поэтому можете воспользоваться этим пакетом, если вдруг решите создать похожее расширение или плагин для IDE на основе JavaScript.
Немного фактов
Теперь у нас есть 22″ экраны с расширением 1920×1080. Поэтому нет необходимости ограничиваться 80 символами в строке, хотя максимальный лимит по знакам установить все-таки стоит. Происхождение ограничения в 80 знаков представлено ниже:
Специально для сайта ITWORLD.UZ. Новость взята с сайта NOP::Nuances of programming