
Я описал инструменты и методы для новичков, имеющих только общее представление в данной теме. Если вы более опытный практик, вам нужны вторая часть о представлении вектора и третья — тематическое моделирование и конвейеры. Конечно, в этой области есть свой жаргон. Он может немного напугать, но я сведу технические термины к минимуму.
Вам понадобится базовое понимание Python и какой-то опыт в машинном обучении желателен, но не обязателен. Как всегда, я даю ссылки на документацию там, где в объяснениях или приёмах не останавливаюсь на деталях.
Токенизация
Токен — это последовательность символов в документе, имеющая значение для анализа. Обычно это отдельные слова, но не всегда. Документ — это коллекция текста. Им может быть твит, книга или что-то еще. Признаки хороших токенов:
- Хранятся в перечисляемых структурах (список, генератор) для упрощения анализа в будущем.
- Имеют единый регистр для одной цели.
- Содержат только буквы и цифры.
Пример: токенизация
import re
def tokenize(text):
text = text.lower()
text = re.sub(r'[^a-zA-Z ^0-9]', '', str(text))
return text.split()
# Используем оригинал текста выше
tokens = tokenize(sample_text)
tokens[:10]
____________________________________________________________________
['a', 'token', 'is', 'a', 'sequence', 'of', 'characters', 'in', 'a', 'document']
Подсчёт слов
Теперь, когда у нас есть токены, мы можем приступить к самому простому анализу. Подсчитаем количество слов через Counter.
from collections import Counter
def word_counter(tokens):
word_counts = Counter()
word_counts.update(tokens)
return word_countsword_count =
word_counter(tokens)
word_count.most_common(5)
____________________________________________________________________
[('a', 7), ('of', 4), ('in', 4), ('be', 4), ('an', 3)]
И отобразим на гистограмме:
import matplotlib.pyplot as plt x = list(word_count.keys())[:10] y = list(word_count.values())[:10] plt.bar(x, y) plt.show();
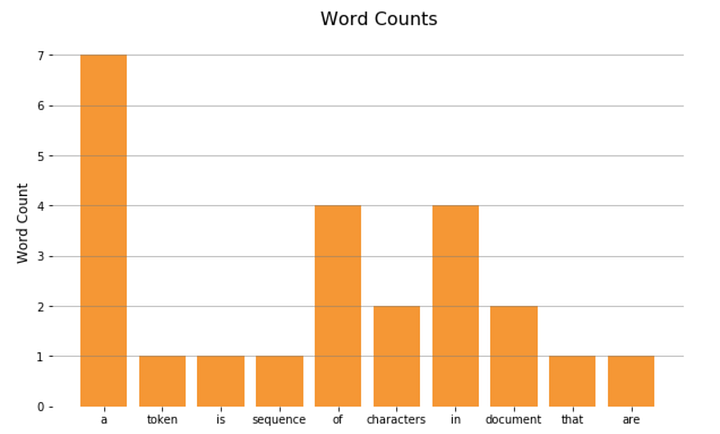
3. Состав документа
Количество слов может быть полезно, но обычно требуется более глубокий анализ, отвечающий на вопросы бизнеса, особенно когда данные состоят не из одного документа. Мы можем настроить себя на успех, создав Pandas DataFrame, содержащий функции, возвращающие:
- Количество и процент документов с токеном.
- Количество токенов.
- Их ранг по частотности употребления по отношению к другим токенам.
- Процент токенов от общего состава документа.
- Текущую сумму этих процентов.
Пример: анализ состава документов с DataFrame
import pandas as pddef count(docs):
word_counts = Counter()
appears_in = Counter()
total_docs = len(docs)
for doc in docs:
word_counts.update(doc)
appears_in.update(set(doc))
temp = list(zip(word_counts.keys(), word_counts.values()))
# Колонки слов и количества
wc = pd.DataFrame(temp, columns = ['word', 'count'])
# Колонка ранга
wc['rank'] = wc['count'].rank(method='first', ascending=False)
# Колонка с общим процентом
total = wc['count'].sum()
wc['pct_total'] = wc['count'].apply(lambda x: x / total)
# Колонка с кумулятивным общим процентом
wc = wc.sort_values(by='rank')
wc['cul_pct_total'] = wc['pct_total'].cumsum()
# Появляется в колонке
t2 = list(zip(appears_in.keys(), appears_in.values()))
ac = pd.DataFrame(t2, columns=['word', 'appears_in'])
wc = ac.merge(wc, on='word')
# Появляется в колонке процентов
wc['appears_in_pct'] = wc['appears_in'].apply(lambda x: x / total_docs)
return wc.sort_values(by='rank')
wc = count([tokens])wc.head()
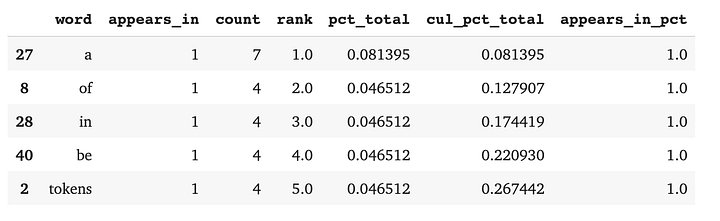
С помощью DataFrame мы видим график функции распределения вероятностей, показывающий, как ранг токена связан с совокупным составом наших документов:
import seaborn as sns sns.lineplot(x = 'rank', y = 'cul_pct_total', data = wc) plt.show();
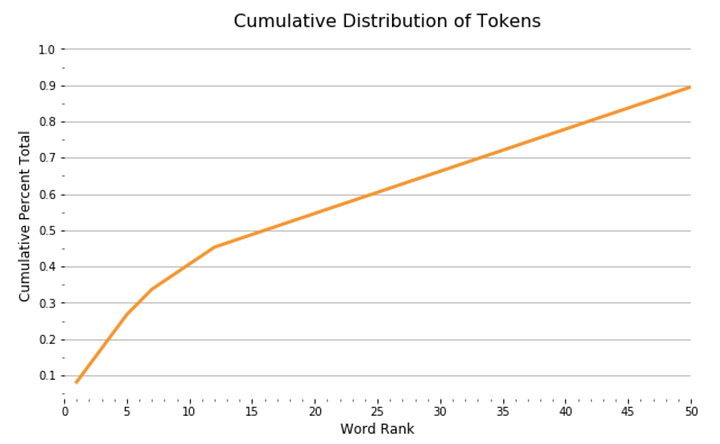
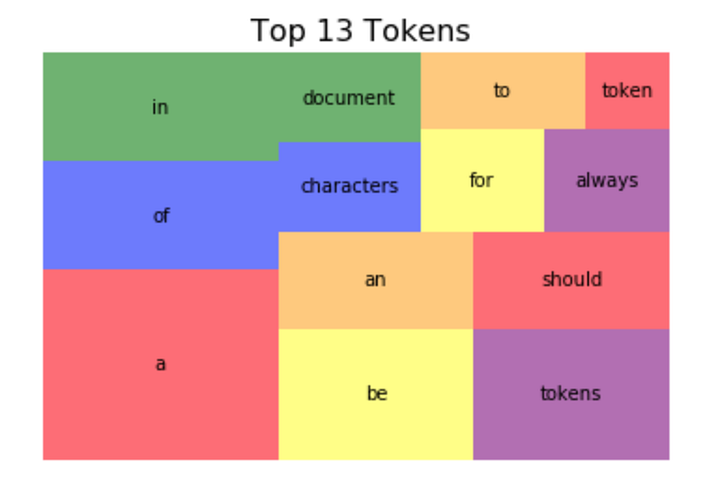
Из графика видно, что 13 наиболее употребимых токенов составляют 45% документа, а после распределение выглядит довольно равномерным. Мы можем увидеть относительный процент этих токенов в составе документа в виде сплошных занимаемых ими участков документа:
import squarify
wc_top13 = wc[wc['rank'] <= 13]
squarify.plot(sizes=wc_top13['pct_total'], label=wc_top13['word'], alpha=.8 )
plt.axis('off')
plt.show();
Эти примеры демонстрируют принципы, необходимые для более глубокого понимания мира обработки естественного языка. Токенизация, подсчёт слов и анализ состава документов — основополагающие концепции. Мы могли бы написать целую библиотеку с нуля, но обычно это не самый эффективный способ решения проблем. Существует зоопарк библиотек с открытым кодом, но только одна из них — лидер в области.
4. Введение в SpaCy
SpaСy — свободная, открытая библиотека Python для решения передовых задач NLP, разработанная Explosion. Она не хранит повторяющиеся компоненты документов в разных структурах данных. Вместо этого SpaСy индексирует компоненты и хранит уточняющую информацию. Поэтому её считают эффективнее в проектах производственного класса, чем библиотеки вроде NLTK. Токены в SpaCy:
import spacy
nlp = spacy.load("en_core_web_lg")
def spacy_tokenize(text):
doc = nlp.tokenizer(text)
return [token.text for token in doc]
spacy_tokens = spacy_tokenize(sample_text)
spacy_tokens[:10]
____________________________________________________________________
['a', 'token', 'is', 'a', 'sequence', 'of', 'characters', 'in', 'a', 'document']
5. Стоп-слова
Слова “I”, “and”, “of” и тому подобные почти не имеют смысловой нагрузки. Мы называем их стоп-словами и в анализ не включаем. Большинство библиотек имеют встроенный список часто используемых английских слов. Союзов, артиклей, наречий, предлогов и общеупотребимых глаголов. Однако лучшая практика — настройка списка под задачу.
Пример удаления стоп-слов:
spacy_stopwords = spacy.lang.en.stop_words.STOP_WORDS
def remove_stopwords(tokens):
cleaned_tokens = []
for token in tokens:
if token not in spacy_stopwords:
cleaned_tokens.append(token)
return cleaned_tokens
cleaned_tokens = remove_stopwords(spacy_tokens)
cleaned_tokens[:10]
____________________________________________________________________
['A', 'token', 'sequence', 'characters', 'document', 'useful', 'analytical', 'purpose', '.', 'Often']
6. Леммы
Лемматизация — поиск леммы слова или корневого слова. Говоря простым языком, лемма — это то слово, которое можно найти в словаре. Например, бег, бежит, бегущий, бежал — формы одной и той же лексемы (слова) с леммой “бег”. Пример лемматизации:
def spacy_lemmatize(text):
doc = nlp.tokenizer(text)
return [token.lemma_ for token in doc]
spacy_lemmas = spacy_lemmatize(sample_text)
spacy_lemmas[:10]
____________________________________________________________________
['A', 'token', 'be', 'a', 'sequence', 'of', 'character', 'in', 'a', 'document']
Заключение
Токены, состав документа, стоп-слова, леммы — все они играют свою роль в обработке естественного языка, хотя они довольно просты сами по себе. Мой следующий пост NLP в Python: представления вектора погрузит нас глубже в тему NLP.
Специально для сайта ITWORLD.UZ. Новость взята с сайта NOP::Nuances of programming