
Или причины избегать npm и отказаться от Google Play
В Kalisio мы разрабатываем геопространственное программное обеспечение с открытым исходным кодом — то есть программное обеспечение, которое управляет геолокационными активами, но более дружественным и ориентированным на бизнес способом, чем обычно предоставляет GISs. Мы создали сильную экосистему, состоящую из различных инструментов и приложений, предоставляя десятки веб-сервисов для наших решений в качестве SaaS:
- Kaabah, решения для построения и операций с инфраструктурой Docker Swarm.
- Kargo, решение на базе Docker для развертывания сервисов.
- Krawler, минималистичный инструмент типа извлечение-преобразование-загрузка.
- Weacast, платформа для сбора, демонстрации и использования данных о прогнозах погоды.
- KDK, набор средств разработки для упрощения построения геопространственных веб-приложений.
- Kano, карта и обозреватель прогноза погоды в 2D/3D.
- Akt’n’Map, приложение для управления событиями реального времени “в поле”.
Такие приложения, как Kano или Akt’n’Map, были разработаны как набор слабо связанных модулей с использованием KDK, чтобы предотвратить создание монолитного программного обеспечения и обеспечить разделение проблем (SoC), а также облегчить обслуживание по крайней мере с точки зрения исходного кода.
Кроме того, мы управляем выделенными инфраструктурами с помощью различных экземпляров этих решений, чтобы иметь возможность одновременно запускать нашу собственную производственную версию, а также бета- и альфа-версии в дополнение к индивидуальным версиям для некоторых клиентов. Как следствие, мы должны полагаться на предсказуемый и в основном автоматизированный процесс выпуска приложений.
Конвейер CI/CD
Основной целью конвейера непрерывной интеграции и развертывания (CI/CD) является сборка артефактов приложений (образов Docker для веб-приложений или пакетов мобильных приложений) и развертывание их в средах, подобных производственной, для тестирования и использования. Схема конвейера:
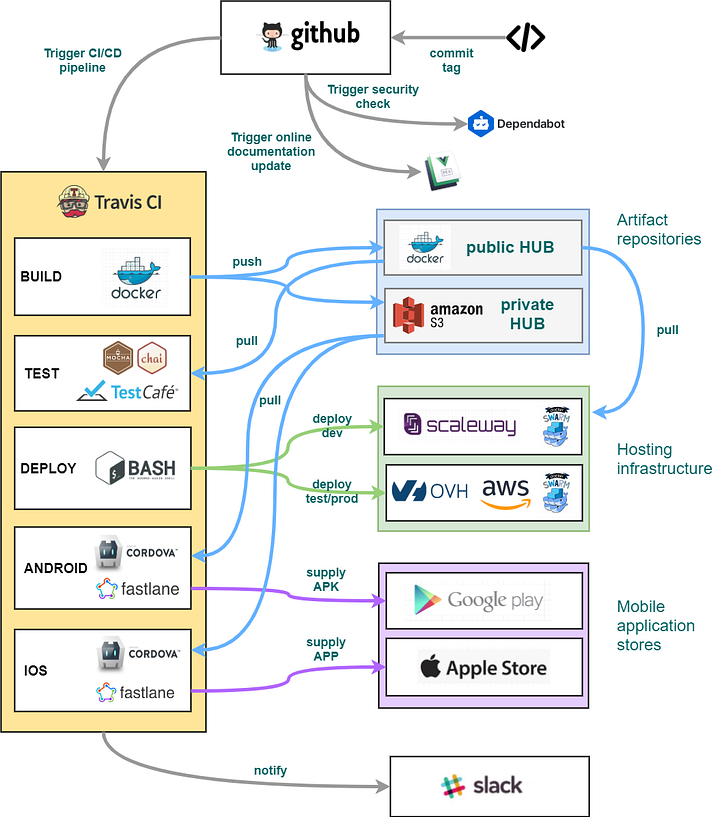
Операции на каждом этапе:
- BUILD: Извлечение исходного кода для создания контейнера и выполнения веб-приложения.
- TEST: Выполнение бэкенд- и фронтенд-тестов с использованием образа приложения.
- DEPLOY: Встраивание веб-приложения в целевую инфрструктуру.
- ANDROID: Создание Android APK для отправки в Google Play.
- IOS: Создание iOS IPA для отправки в App Store Connect.
Выглядит довольно просто, правда? Однако, как будет объяснено далее, нам было трудно заставить всё это работать гладко.
Когда лучшие практики — не лучшие
Менеджер пакетов
npm — решение для управления модулями с помощью Node.JS. Он прост и отлично подходит для независимых модулей производственного класса. Однако у него есть некоторые недостатки, когда речь заходит об управлении пакетами во время разработки, особенно в большой экосистеме.
Во-первых, использование неопубликованных (например, незавершенных) пакетов сильно отличается от использования выпущенных пакетов. Простого npm install достаточно во втором случае, но в первом случае для получения полного дерева зависимостей вам нужно клонировать все репозитории вашего дерева зависимостей, которые в настоящее время находятся в разработке, и связать их.
Во-вторых, связывание происходит на глобальном уровне Node.JS, так что вы не можете легко иметь несколько версий одного модуля в вашей среде.
Наконец, когда у вас есть большое дерево зависимостей и выпускаются модули с глубокими зависимостями, вы должны выполнить операцию обновления для всех зависимых модулей. Это может быть болезненно. Действительно, если вы хотите иметь предсказуемые сборки, то должны полагаться на файлы блокировки. При работе с большой базой кода это означает необходимость внесения изменений в десятки репозиториев.
Примечание: из-за некоторых изменений в том, как npm управляет связанными модулями, мы фактически предпочитаем использовать Yarn. Но анализ не ограничивается только этим.
Магазины приложений
Магазины приложений на самом деле предназначены для нативных , а не веб-приложений, где у вас есть физическое разделение между клиентом и сервером.
Как следствие, естественным процессом выпуска приложения является продвижение одного пакета (например, APK или IPA) из одного состояния публикации (например, частный альфа-релиз) в следующее состояние (например, публичный бета-релиз). Это означает, что вы не можете изменить конфигурацию пакета по умолчанию в зависимости от состояния публикации.
Поскольку клиентское приложение должно быть в состоянии — по крайней мере работать без подключения к серверу (пользователь в данном случае не указывает браузеру правильный адрес сервера) — естественно сделать URL целевого сервера частью конфигурации.
Но если у вас разные конечные точки для разных версий, то придется полагаться на фиксированный сторонний сервер для ретрансляции запросов или встроенный графический интерфейс, позволяющий пользователям изменять URL целевого сервера (подверженный ошибкам и не очень удобный пользователю). Ещё более сложно то, что вы можете иметь только одну версию приложения, установленную в один момент времени, так как все они имеют один и тот же идентификатор приложения. Если некоторые из ваших пользователей используют альфа-версию, то они не могут использовать производственную версию.
Чувствительные данные
Поскольку приложение зависит от сторонних сервисов, его конфигурация должна включать конфиденциальные данные, такие как ключи API, учетные данные SSH и так далее, чтобы получить доступ к необходимым из них. Конечно, эти данные не должны находиться в системе контроля версий, если ваши репозитории общедоступны.
Во-первых, вы можете использовать зашифрованные переменные среды, заданные либо в файле сборки, либо в настройках репозитория. Но когда у вас много переменных окружения, это становится сложным и теряется гибкость: изменение значения требует дополнительных операций для шифрования.
Кроме того, этот способ плох тогда, когда у вас различные конфигурации одного и того же приложения для альфа -, бета- и производственных версий. Вы должны дублировать каждую переменную для каждой доступной конфигурации, используя соглашение об именовании: VARIABLE_ALPHA, VARIABLE_BETA, VARIABLE_PROD.
И последнее, но не менее важное: такой способ не работает, если некоторые из ваших секретов — это не переменные окружения, а файлы. В этом случае можно создать secrets.tar, содержащий все защищенные файлы, и зашифровать его в secrets.tar.enc с помощью Travis CLI. Этот файл будет расшифрован перед сборкой или всякий раз, когда вам понадобится что-то внутри.
Однако действуют те же ограничения: вы должны дублировать каждый файл для каждой доступной конфигурации, используя соглашение об именовании или пути, а изменение любого файла требует дополнительных операций. Кроме того, вам все еще нужно защищенное хранилище для необработанных секретных файлов.
Разделение фронтенда и бэкенда
Это концептуальное разделение превратилось в специализированные роли разработчиков, что по-прежнему норма во всей отрасли.
Среди многих аргументов в пользу разделения, один из самых ошибочных из них, вероятно, заключается в том, что изменения в бэкенде не повлияют на фронтенд — и наоборот. Это верно только тогда, когда вы поддерживаете обратную совместимость API. Дело в том, что мы разрабатываем фичи. Эти фичи не являются ни внутренними, ни внешними. В большинстве случаев эти фичи — и то, и другое.
И в этом случае усилий при таком разделении ролей прикладывается больше, особенно если у вас много модулей. Чтобы зафиксировать какие-либо изменения, необходимо сделать две синхронные фиксации, а не одну. Чтобы выпустить новую функцию, один и тот же процесс применяется дважды. При работе с большой кодовой базой это означает необходимость внесения изменений и других действий в десятках репозиториев.
Масштабируемость команды также является аргументом в пользу разделения, но при работе с небольшой командой (как работаем мы) лучше уменьшить недопонимание, облегчая разработку приложений.
Наконец, некоторые части наших модулей написаны с использованием изоморфного JavaScript, работающего как на клиенте, так и на сервере, поэтому разделение на фронтенд и бэкенд бессмысленно.
SemVer
Строгое следование SemVer фактически требует открытого API, который отлично подходит для библиотек и модулей, интегрируемых в стороннее приложение, но не для самого приложения.
В этом случае пользователи ожидают, что второстепенные версии будут обратно совместимы с данными, созданными предыдущими второстепенными версиями, но с несколькими новыми функциями или улучшениями в рабочем процессе существующих функций. Основные выпуски могут нарушить эту обратную совместимость, удалив существующие функции и определив новый формат данных.
Мы придумали свои лучшие практики
У нас уже есть проверенное и надежное решение для управления несколькими версиями кода: ветви Git. Идея в том, чтобы как можно больше придерживаться этой простой концепции и соответственно управлять процессом.
- Наш CI/CD поставляется в трех различных вариантах в зависимости от текущей ветви Git.
- dev: для развертывания текущей версии development/alpha, связанной с основной ветвью кода.
- test: для развертывания текущей промежуточной/бета-версии, связанной с тестовой ветвью кода.
- prod: для развертывания текущей рабочей версии, связанной с тегами версий в тестовой ветви кода.
Артефакты выходного образа Docker используют пререлизную нотацию SemVer, чтобы определить, какой тип был использован для его создания — например, 1.0.0-dev или 1.3.0-test.
2.Мы создали простой интерфейс командной строки, представляющий собой мультиплексор для обычных команд git/npm/yarn, используемых при разработке KDK-приложений.
Это позволяет нам легко клонировать, устанавливать, связывать, разъединять и переключать ветви приложения и всех зависимых модулей с помощью одной команды.
CLI опирается на то, что мы называем файлом рабочей области, определяя дерево зависимостей между вашим приложением и разрабатываемыми модулями. Очень простой пример рабочего пространства для нашего шаблона приложения можно найти здесь. Вы можете создать новую рабочую среду с помощью нескольких команд:
// Клонируем требуемые репозитории с целевой ветвью. kdk your_workspace.js --clone your_branch // Устанавливаем зависимости во все требуемые модули. kdk your_workspace.js --install // Связываем модули соответственно дереву зависимостей. kdk your_workspace.js --link
Ключевой момент: мы используем один и тот же процесс независимо от ветки (dev, test или prod).
Примечание: в производстве мы клонируем из тега вместо ветви, но с точки зрения Git это одно и то же, а именно — конкретный коммит.
3. Мы декларировали разные приложения для каждого типа ветви в разных мобильных магазинах. Мы строим гибридные мобильные приложения с помощью Cordova. Каждое приложение публикуется только с состоянием, связанным с соответствующим типом ветви:
- Приватная альфа-версия для разработки.
- Публичная бета-версия для тестирования.
- Публичная версия для производственной среды.
 Наши разные Akt’n’Map
Наши разные Akt’n’Map4. Мы используем приватный репозиторий GitHub, называемый рабочей областью, в качестве защищенного хранилища конфигурации приложения. Каждая рабочая область имеет вложенные папки для каждой ветви (dev, test, prod), а также общую папку, содержащую общие файлы конфигурации.
Чтобы избежать дублирования большого количества переменных окружения, мы также объединили их .env файлы, содержащиеся в общей и вложенных папках для создания конечной среды.
 Пример рабочего пространства приложения
Пример рабочего пространства приложения5. Мы держим фронтенд- и бэкенд-код вместе в наших модулях, чтобы писать определенный набор функциональных возможностей с точки зрения пользователя (например, управление профилями и выставлением счетов).
Поскольку пакет фронтенда фактически генерируется при построении приложения с помощью webpack, мы избегаем болезненной задачи управления конфигурацией сборки фронтенда в каждом модуле.
Так как мы используем Quasar или Vue.js, то публикуем только необработанные файлы компонентов (например,*.vue) в модулях, которые затем обрабатываются webpack и динамически загружаются в приложение во время выполнения.
Заключение
Мы не говорим, что наше решение лучше, чем хорошо известные подходы, но полагаем, что лучшие практики все ещё нуждаются в доработке, особенно в том, что касается больших экосистем и сложных приложений.
Некоторые усилия уже приложены в этом направлении, но очевидно, что нет универсального решения. Например, Google создал repo — CLI для упрощения работы с несколькими репозиториями при разработке на Android. Это что-то похожее на наш инструмент.
С помощью субмодулей Git-репозиторий может использовать код из других репозиториев, но без автоматического обновления и поддержки ветвей. Это просто указатель на конкретный коммит репозитория субмодуля.
Инструменты монорепозитория, такие как Lerna, частично решают эту проблему, упрощая физическую структуру кодовой базы путем объединения репозиториев. Однако вам все равно придется управлять логической структурой кода, обновляя и выпуская один и тот же набор пакетов. Аналогично Bit изолирует строительные блоки (компоненты и библиотеки) из любого репозитория, который будет использоваться в любом другом репозитории, но вам все равно придется управлять логической структурой.
Мы знаем, что не можем достичь идеального решения. Но вот, чему мы научились:
Какой бы инструмент вы ни использовали, если придется выполнять отдельные действия для каждого логического компонента, чтобы выпустить приложение, то вы столкнетесь с огромными накладными расходами.
Нам не нужно выполнять определенные действия для выпуска, за исключением действий, уже выполняемых каждый день разработчиками с помощью git: commit, merge и tag branch. Еще одним преимуществом является полная сегрегация сред, от инфраструктур до пакетов приложений, что значительно упрощает жизненный цикл приложения и позволяет избежать загрязнения [пред]продакшна проблемами, связанными с разработкой. Конечно, у нашего подхода есть и недостатки:
- Отказ от npm для релизов контринтуитивен, а связывание модулей приводит к дублированию зависимостей в рабочей среде.
- Управление несколькими инфраструктурами, приложениями и т.д. усложняет конфигурирование.
- При использовании динамического импорта для каждого файла компонента создаются фрагменты, даже если некоторые из них не используются в конечном приложении.
- Без процесса сборки для интерфейсных файлов в модулях мы выполняем только интерфейсное тестирование на уровне приложения.
Специально для сайта ITWORLD.UZ. Новость взята с сайта NOP::Nuances of programming