Итак, к чему я. Увлеклась я изучением такого популярного python’а. А лучший способ изучить что-либо, как вы знаете, — практика. А еще я интересуюсь недвижимостью. И попалась мне на глаза интересная задачка о недвижимости в Москве: проранжировать округа Москвы по усредненной стоимости аренды средней однушки? Батюшки, я подумала, да тут вам и геолокация, и выгрузка с сайта, и анализ данных — прекрасная практическая задача.
Воодушевившись замечательными статьями тут на Хабре (в конце статьи добавлю ссылки), приступим!
Задача у нас пройтись по существующим инструментам внутри python’а, разобрать технику — как решать подобные задачи и провести время с удовольствием, а не только с пользой.
Скрапинг Циана
На середину марта 2020 года на циане получилось собрать почти 9 тысяч предложений об аренде 1-комнатной квартиры в Москве, сайт отображает 54 страницы. Работать будем с jupyter-notebook 6.0.1, python 3.7. Прогружаем данные с сайта и сохраняем в файлы с помощью библиотеки requests.
Чтобы сайт нас не забанил, замаскируемся под человека, добавив задержку в запросах и задав хедер, чтобы со стороны сайта мы выглядели, как очень шустрый человек, делающий запросы через браузер. Не забываем каждый раз проверять ответ от сайта, а то вдруг нас раскрыли и уже забанили. Более подробно и детально про скрапинг сайтов можно почитать, например, тут: Web Scraping с помощью python.
Удобно так же добавить декораторы для оценки скоростей выполнения наших функций и ведения логов. Настройка level=logging.INFO позволяет указать тип выводимых в лог сообщений. Так же можно донастроить модуль для вывода лога в текстовый файл, для нас это излишне.
def timer(f):
def wrap_timer(*args, **kwargs):
start = time.time()
result = f(*args, **kwargs)
delta = time.time() - start
print (f'Время выполнения функции {f.__name__} составило {delta} секунд')
return result
return wrap_timer
def log(f):
def wrap_log(*args, **kwargs):
logging.info(f"Запущена функция {f.__doc__}")
result = f(*args, **kwargs)
logging.info(f"Результат: {result}")
return result
return wrap_log
logging.basicConfig(level=logging.INFO)
@timer
@log
def requests_site(N):
headers = ({'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'})
pages = [106 + i for i in range(N)]
n = 0
for i in pages:
s = f"https://www.cian.ru/cat.php?deal_type=rent&engine_version=2&page={i}&offer_type=flat®ion=1&room1=1&type=-2"
response = requests.get(s, headers = headers)
if response.status_code == 200:
name = f'sheets/sheet_{i}.txt'
with open(name, 'w') as f:
f.write(response.text)
n += 1
logging.info(f"Обработана страница {i}")
else:
print(f"От страницы {i} пришел ответ response.status_code = {response.status_code}")
time.sleep(np.random.randint(7,13))
return f"Успешно загружено {n} страниц"
requests_site(300)
Единый датафрейм
Для скрапинга страниц на выбор BeautifulSoup и lxml. Используем «прекрасный суп» просто за его прикольное название, хотя, говорят, что lxml быстрее.
Можно сделать красиво, взять список файлов из папки с помощью библиотеки os, отфильтровать нужные нам по расширению и пройтись по ним. Но мы сделаем проще, так как точное число файлов и точные их названия нам известны. Разве что добавим украшательство в виде прогресс бара, используя библиотеку tqdm
from bs4 import BeautifulSoup
import re
import pandas as pd
from dateutil.parser import parse
from datetime import datetime, date, time
def read_file(filename):
with open(filename) as input_file:
text = input_file.read()
return text
import tqdm
site_texts = []
pages = [1 + i for i in range(309)]
for i in tqdm.tqdm(pages):
name = f'sheets/sheet_{i}.txt'
site_texts.append(read_file(name))
print(f"Прочитано {len(site_texts)} файлов.")
def parse_tag(tag, tag_value, item):
key = tag
value = "None"
if item.find('div', {'class': tag_value}):
if key == 'link':
value = item.find('div', {'class': tag_value}).find('a').get('href')
elif (key == 'price' or key == 'price_meter'):
value = parse_digits(item.find('div', {'class': tag_value}).text, key)
elif key == 'pub_datetime':
value = parse_date(item.find('div', {'class': tag_value}).text)
else:
value = item.find('div', {'class': tag_value}).text
return key, value
def parse_digits(string, type_digit):
digit = 0
try:
if type_digit == 'flats_counts':
digit = int(re.sub(r" ", "", string[:string.find("пр")]))
elif type_digit == 'price':
digit = re.sub(r" ", "", re.sub(r"₽", "", string))
elif type_digit == 'price_meter':
digit = re.sub(r" ", "", re.sub(r"₽/м²", "", string))
except:
return -1
return digit
def parse_date(string):
now = datetime.strptime("15.03.20 00:00", "%d.%m.%y %H:%M")
s = string
if string.find('сегодня') >= 0:
s = "{} {}".format(now.day, now.strftime("%b"))
s = string.replace('сегодня', s)
elif string.find('вчера') >= 0:
s = "{} {}".format(now.day - 1, now.strftime("%b"))
s = string.replace('вчера',s)
if (s.find('мар') > 0):
s = s.replace('мар','mar')
if (s.find('фев') > 0):
s = s.replace('фев','feb')
if (s.find('янв') > 0):
s = s.replace('янв','jan')
return parse(s).strftime('%Y-%m-%d %H:%M:%S')
def parse_text(text, index):
tag_table = '_93444fe79c--wrapper--E9jWb'
tag_items = ['_93444fe79c--card--_yguQ', '_93444fe79c--card--_yguQ']
tag_flats_counts = '_93444fe79c--totalOffers--22-FL'
tags = {
'link':('c6e8ba5398--info-section--Sfnx- c6e8ba5398--main-info--oWcMk','undefined c6e8ba5398--main-info--oWcMk'),
'desc': ('c6e8ba5398--title--2CW78','c6e8ba5398--single_title--22TGT', 'c6e8ba5398--subtitle--UTwbQ'),
'price': ('c6e8ba5398--header--1df-X', 'c6e8ba5398--header--1dF9r'),
'price_meter': 'c6e8ba5398--term--3kvtJ',
'metro': 'c6e8ba5398--underground-name--1efZ3',
'pub_datetime': 'c6e8ba5398--absolute--9uFLj',
'address': 'c6e8ba5398--address-links--1tfGW',
'square': ''
}
res = []
flats_counts = 0
soup = BeautifulSoup(text)
if soup.find('div', {'class': tag_flats_counts}):
flats_counts = parse_digits(soup.find('div', {'class': tag_flats_counts}).text, 'flats_counts')
flats_list = soup.find('div', {'class': tag_table})
if flats_list:
items = flats_list.find_all('div', {'class': tag_items})
for i, item in enumerate(items):
d = {'index': index}
index += 1
for tag in tags.keys():
tag_value = tags[tag]
key, value = parse_tag(tag, tag_value, item)
d[key] = value
results[index] = d
return flats_counts, index
from IPython.display import clear_output
sum_flats = 0
index = 0
results = {}
for i, text in enumerate(site_texts):
flats_counts, index = parse_text(text, index)
sum_flats = len(results)
clear_output(wait=True)
print(f" Файл {i + 1} flats = {flats_counts}, добавлено итого {sum_flats} квартир")
print(f"Итого sum_flats ({sum_flats}) = flats_counts({flats_counts})")
Интересным ньюансом оказалось то, что цифра, указанная сверху страницы и обозначающая общее количество квартир, найденных по запросу, отличается от страницы к странице. Так, в нашем примере это 5 402 предложение отсортированы по умолчанию находится в диапазоне от 5343 до 5402, постепенно снижаясь с увеличением номера страницы запроса (но не на количество отображенных объявлений). К тому же оказалось возможным продолжать выгружать страницы за пределами ограничения в количестве страниц, указанных на сайте. В нашем случае на сайте было предложено всего 54 страницы, но мы смогли выгрузить 309 страниц, только с более старыми объявлениями, итого 8640 объявлений об аренде квартир.
Расследование данного факта оставим за рамками данной статьи.
Обработка датафрейма
Итак, имеем единый датафрейм с сырыми данными по 8640 предложениям. Проведем поверхностный анализ средних и медианных цен по округам, посчитаем среднюю стоимость аренды квадратного метра квартиры и стоимость квартиры в округе «в среднем».
Будем исходить из следующих допущений для нашего исследования:
- Отсутствие повторов: все найденные квартиры — действительно существующие квартиры. На первом этапе повторяющиеся квартиры по адресу и по квадратуре мы отсеяли, но если у квартиры немного разная квадратура или адрес — такие варианты считаем разными квартирами.
- Средняя квартира в округе — квартира со средней квадратурой для округа.
Сейчас можно уйти в глубокие обсуждения — что считать «средней» квартирой в округе? Можно закопаться (и это будет правильно) в параметрах каждой найденной квартиры и найди средние значения таких показателей, как площадь, этаж, близость к метро, смежность или раздельность комнат и сан. узла, наличие лоджии или балкона, качество ремонта, год и тип постройки дома и многие другие показатели. Оставим это на будущие «изыскания» и остановимся на определении: среднюю квартиру в округе будем считать по средней квадратуре. А чтобы исключительные варианты или «выбросы» (единичные квартиры с непривычно большим метражом или с неожиданной низкой стоимостью) не искажали наш результат, определим их и удалим из исследования.
Нам понадобятся:
price_per_month — цена за месяц ареды в рублях
square — площадь
okrug — округ, в данном исследовании весь адрес нам не интересен
price_meter — цена аренды за 1 кв метр
df['price_per_month'] = df['price'].str.strip('/мес.').astype(int) #price_int
new_desc = df["desc"].str.split(",", n = 3, expand = True)
df["square"]= new_desc[1].str.strip(' м²').astype(int)
df["floor"]= new_desc[2]
new_address = df['address'].str.split(',', n = 3, expand = True)
df['okrug'] = new_address[1].str.strip(" ")
df['price_per_meter'] = (df['price_per_month'] / df['square']).round(2) #price_std
df = df.drop(['index','metro', 'price_meter','link', 'price','desc','address','pub_datetime','floor'], axis='columns')
Теперь «займемся» выбросами вручную по графикам. Для визуализации данных посмотрим три библиотеки: matplotlib, seaborn и plotly.
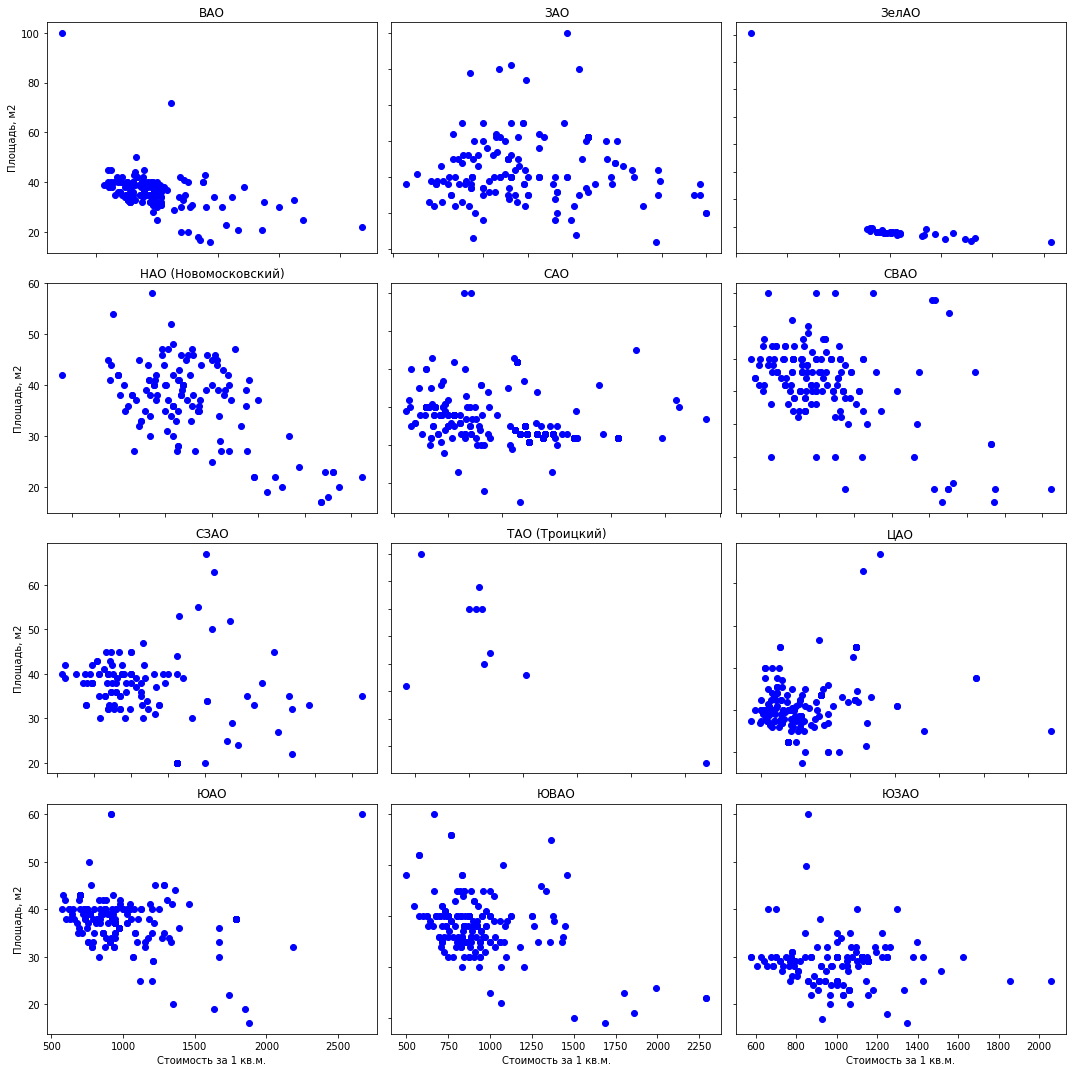
Гистограммы данных. Matplotlib позволяет просто и быстро отобразить все диаграммы по интересующим нас группам данных, большего нам и не надо. Рисунок ниже, по которому всего 1 предложение в Митино не могут служить качественной оценкой средней квартиры, удалим. Еще интересная картира в ЮАО: большинство предложений (более 500 шт) с арендной стоимостью ниже 1000 руб., и всплеск предложений (почти 300 шт) на 1700 руб за квадратный метр. В дальнейшем можно посмотреть почему так происходит — покопавшись в других показателях по этим квартирам.
Всего одна строчка кода дает там гистограммы по сгруппированным наборам данных:
hists = df['price_per_meter'].hist(by=df['okrug'], figsize=(16, 14), color = "tab:blue", grid = True)

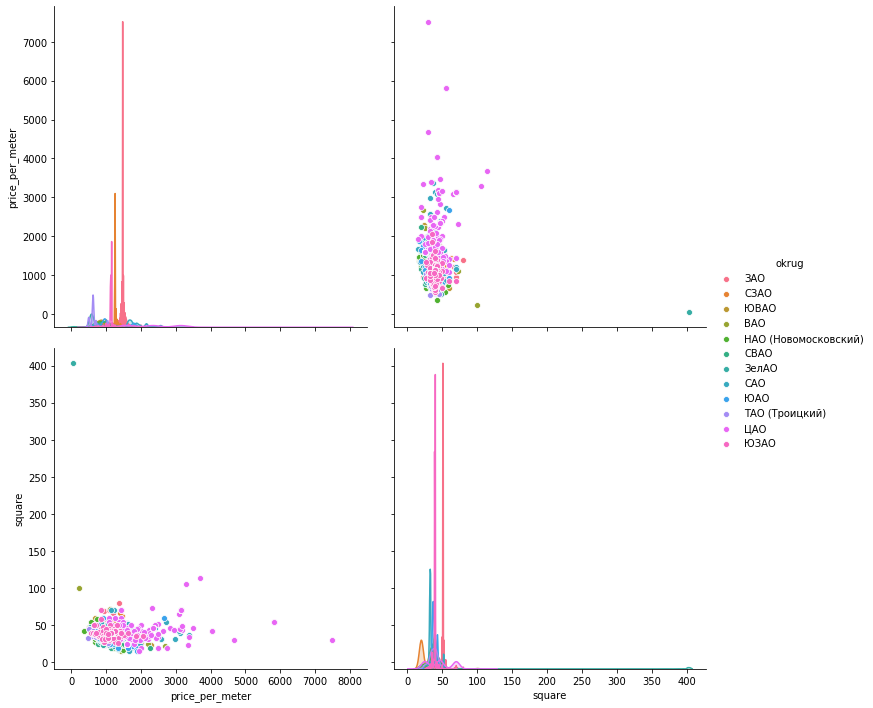
Разброс значений. Ниже представила графики с помощью всех трех библиотек. seaborn по умолчанию — более красивая и яркая, зато plotly позволяет сразу отображать значения при наведении мышки, что нам очень удобно для выбора значений «выбросов», которые мы будем удалять.
matplotlib
fig, axes = plt.subplots(nrows=4,ncols=3,figsize=(15,15))
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
axes = axes.flatten()
axes[i].scatter(group['price_per_meter'],group['square'], color ='blue')
axes[i].set_title(name)
axes[i].set(xlabel='Стоимость за 1 кв.м.', ylabel='Площадь, м2')
axes[i].label_outer()
fig.tight_layout()
seaboarn
sns.pairplot(vars=["price_per_meter","square"], data=df_copy, hue="okrug", height=5)
plotly
Думаю, тут будет достаточно примера по одному округу.
import plotly.express as px
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
fig = px.scatter(group, x="price_per_meter", y="square", facet_col="okrug",
width=400, height=400)
fig.update_layout(
margin=dict(l=20, r=20, t=20, b=20),
paper_bgcolor="LightSteelBlue",
)
fig.show()
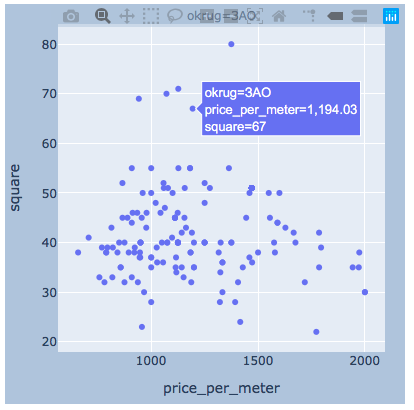
Результаты
Итак, почистив данные, экспертно удалив выбросы, имеем 8602 «чистых» предложения.
Далее, посчитаем основные статистики по данным: среднее, медиану, стандартное отклонение, получаем следующий рейтинг округов Москвы по мере уменьшения средней стоимости арендной платы за среднюю квартиру:

Можно порисовать красивые гистограммы, сравнивая, например, средние и медианные цены в округе:
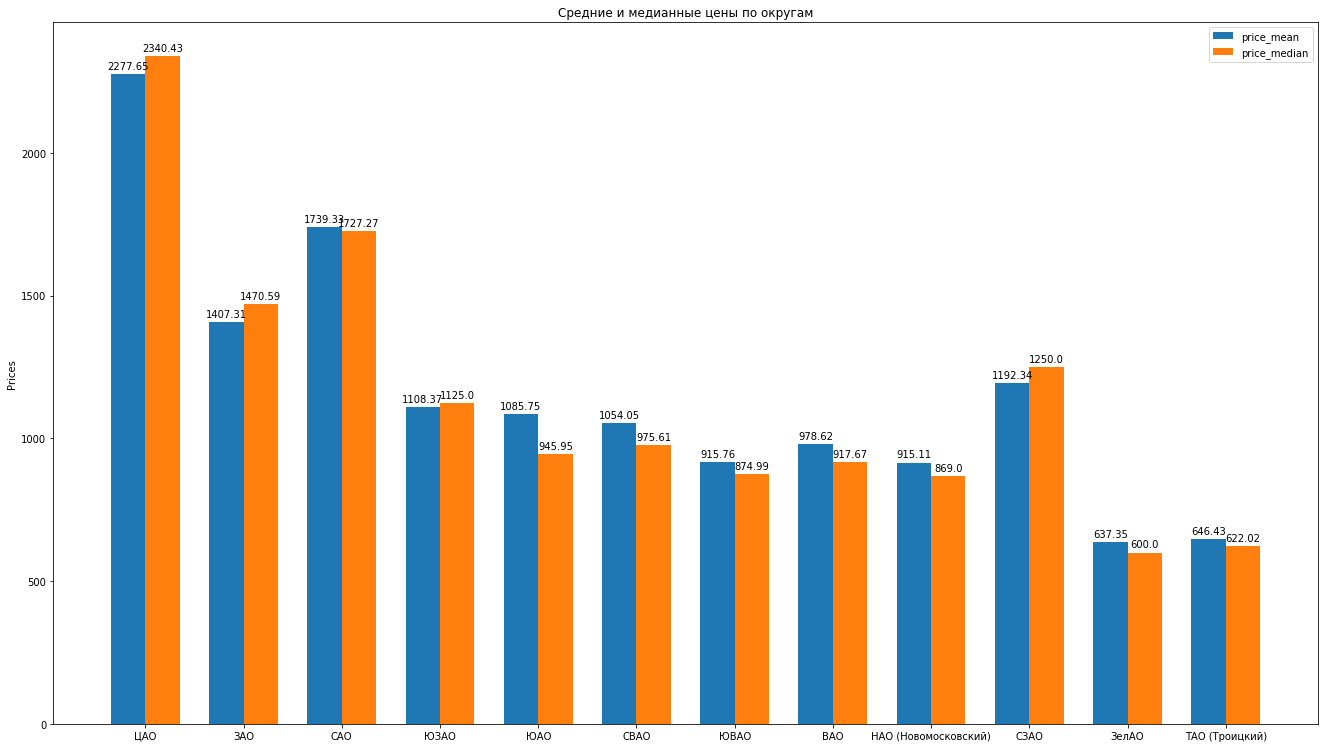
Что можно еще сказать про структуру предложений по аренде квартир на основе данных:
- В ЦАО, ЗАО квартиры несколько переоценены, так как средние цены на квартиры выше, чем цена на аренду в среднем. Это некий введеный нами “индекс” стоимости аренды квартиры в округе, стоимость средней квартиры по средней цене в округе (средняя квадратура в округе на среднюю цену в округе). Следует заменить, что это тренировочное упражнение и в бою, конечно же, следует гораздо ответственнее и сложнее отнестись к созданию индекса цены, возможно, следует ввести много других параметров, от которых будет зависеть “эталонная” цена аренды. А вот в ВАО и НАО, например, цены слегка занижены.
- Медианные цены тоже представляют достаточно интересную информацию. Среднее значение в целом довольно чувствительно к выбрасам. Это как в анекдотах про «среднюю температуру по больнице». В интернете много статей на простом языке объясняющих разницу между данными статистическими показателями, например «Средние» значения — ваш враг. Как не попасться на удочку усреднения. Медиана же более устойчива к выбросам и позволяет более точно характеризовать предложения. Так, в ЮАО и СВАО, например, медианная цена аренды достаточно ниже, чем средняя цена, а это значит все-таки такая более низкая, чем средняя, цена будет более точно описывать ситуацию с рынком аренды в округе. См. гистограмму.
- Стандартное отклонение характеризует меру разброса значений предложений, насколько “густо” сосредоточены точки, насколько цены колеблются от среднего. Видим, что наибольший разбор у нас в ЦАО, а наименьший — в ЮЗАО и ЗелАО.
Немного о работе с геоданными
Отдельной, невероятно интересной и красивой главой идет тема геоданные, отображение наших данных в привязке к карте. Очень подробно и детально можно посмотреть, например, в статьях:
Визуализация результатов выборов в Москве на карте в Jupyter Notebook
Ликбез по картографическим проекциям с картинками
OpenStreetMap как источник геоданных
Кратко, OpenStreetMap наше все, удобные инструменты это: geopandas, cartoframes (говорят, он уже погиб?) и folium, который мы и будем использовать.
Вот как будут выглядеть наши данные на интерактивной карте.
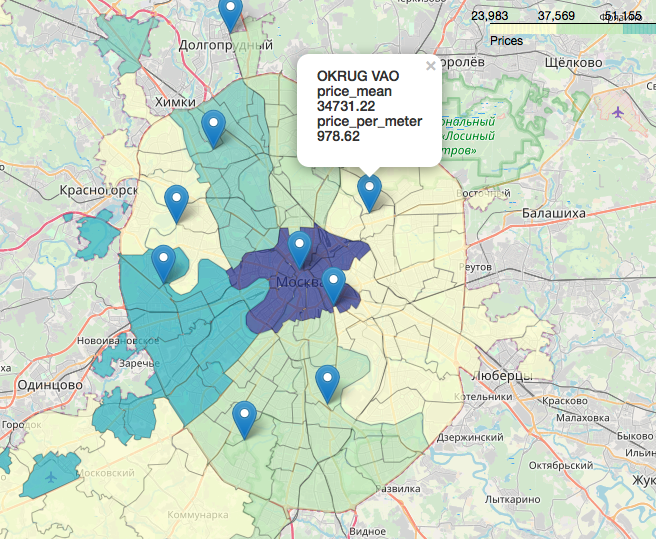
Материалы, которые оказались полезными в работе над статьей:
- «Web Scraping с помощью python»
- «Как я создал веб-скрапер на Python для поиска жилья»
- «Как программисты ищут квартиры»
- «Покупка оптимальной квартиры с R»
- «Визуализация результатов выборов в Москве на карте в Jupyter Notebook»
- «Ликбез по картографическим проекциям с картинками»
- «OpenStreetMap как источник геоданных»
Надеюсь, вам было интересно, как и мне.
Спасибо, что дочитали. Конструктивная критика приветствуется.
Исходники и датасеты выложены на гитхабе тут.
Специально для сайта ITWORLD.UZ. Новость взята с сайта Хабр