
Введение
Аудиоанализ — область, включающая автоматическое распознавание речи (ASR), цифровую обработку сигналов, а также классификацию, тегирование и генерацию музыки — представляет собой развивающийся поддомен приложений глубокого обучения. Некоторые из самых популярных и распространенных систем машинного обучения, такие как виртуальные помощники Alexa, Siri и Google Home, — это продукты, созданные на основе моделей, извлекающих информацию из аудиосигналов.
Обзор аудиофайлов
Аудио фрагменты представлены в формате .wav. Звуковые волны оцифровываются путем выборки из дискретных интервалов, известных как частота дискретизации (как правило, 44,1 кГц для аудио с CD-качеством, то есть 44 100 семплов в секунду).
Каждый семпл представляет собой амплитуду волны в определенном временном интервале, где глубина в битах (или динамический диапазон сигнала) определяет, насколько детализированным будет семпл (обычно 16 бит, т.е. семпл может варьироваться от 65 536 значений амплитуды).
В обработке сигналов семплинг — это преобразование непрерывного сигнала в серию дискретных значений. Частота дискретизации — это количество семплов за определенный фиксированный промежуток времени. Высокая частота дискретизации приводит к меньшей потере информации, но к большим вычислительным затратам.
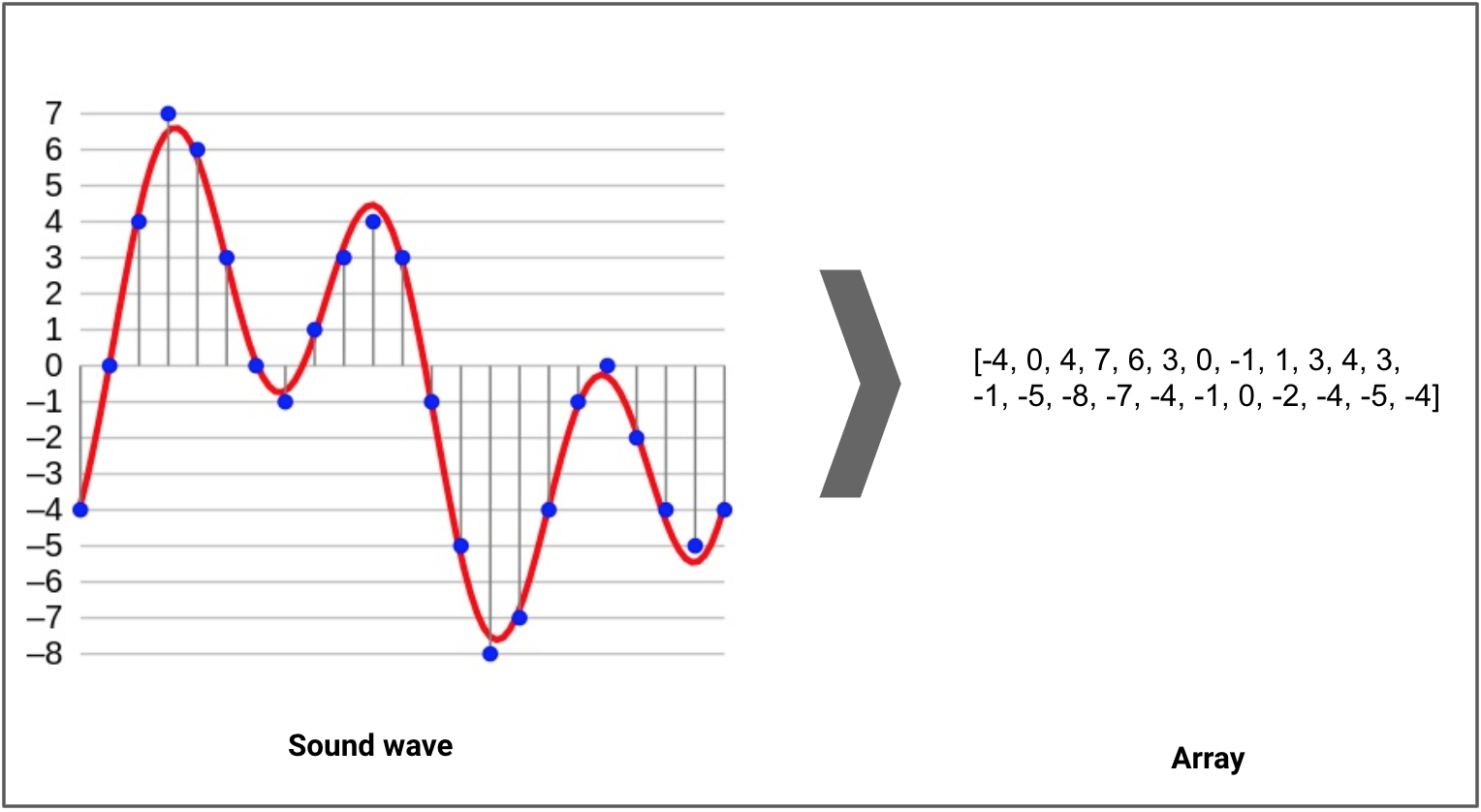 Звуковая волна в цифровом формате обозначена красным цветом, а синим — результат семплинга и 4-битного квантования. Справа находится результирующий массив.
Звуковая волна в цифровом формате обозначена красным цветом, а синим — результат семплинга и 4-битного квантования. Справа находится результирующий массив.Приложения по обработке звука
К ним можно отнести:
- Индексирование музыкальных коллекций согласно их аудиопризнакам.
- Рекомендация музыки для радиоканалов.
- Поиск сходства для аудиофайлов (Shazam).
- Обработка и синтез речи — генерирование искусственного голоса для диалоговых агентов.
Обработка аудиоданных с помощью Python
Звук представлен в форме аудиосигнала с такими параметрами, как частота, полоса пропускания, децибел и т.д. Типичный аудиосигнал можно выразить в качестве функции амплитуды и времени.
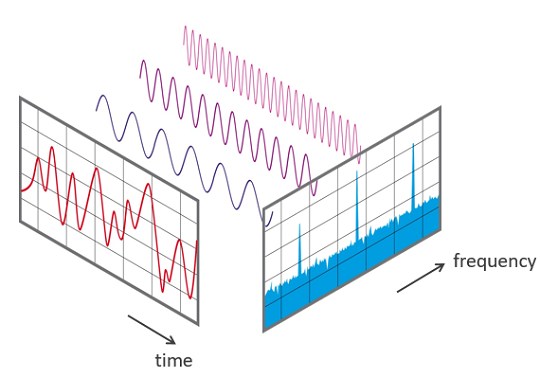 Время/частота.
Время/частота.Некоторые устройства могут улавливать эти звуки и представлять их в машиночитаемом формате. Примеры этих форматов:
- wav (Waveform Audio File)
- mp3 (MPEG-1 Audio Layer 3)
- WMA (Windows Media Audio)
Процесс обработки звука включает извлечение акустических характеристик, относящихся к поставленной задаче, за которыми следуют схемы принятия решений, которые включают обнаружение, классификацию и объединение знаний. К счастью, некоторые библиотеки Python помогают облегчить эту задачу.
Аудио библиотеки Python
Мы будем использовать две библиотеки для сбора и воспроизведения аудио:
1. Librosa
Это модуль Python для анализа звуковых сигналов, предназначенный для работы с музыкой. Он включает все необходимое для создания системы MIR (поиск музыкальной информации) и подробно задокументирован вместе со множеством примеров и руководств.
Установка:
pip install librosa или conda install -c conda-forge librosa
Для повышения мощности декодирования звука можно установить ffmpeg, содержащий множество аудио декодеров.
2. IPython.display.Audio
С помощью IPython.display.Audio можно проигрывать аудио прямо в jupyter notebook.
Сюда загружен случайный аудиофайл. Попробуем передать его в консоль jupyter.
Загрузка аудиофайла:
import librosa audio_data = '/../../gruesome.wav' x , sr = librosa.load(audio_data) print(type(x), type(sr)) #<class 'numpy.ndarray'> <class 'int'> print(x.shape, sr) #(94316,) 22050
Этот фрагмент возвращает звуковой временной ряд в качестве массива numpy с частотой дискретизации по умолчанию 22 кГц моно. Это поведение можно изменить с помощью повторного семплинга на частоте 44,1 кГц.
librosa.load(audio_data, sr=44100)
Повторный семплинг также можно отключить:
librosa.load(audio_path, sr=None)
Частота дискретизации — это количество аудио семплов, передаваемых в секунду, которое измеряется в Гц или кГц.
Проигрывание аудио:
С помощью IPython.display.Audio можно проигрывать аудио в jupyter notebook.
import IPython.display as ipd ipd.Audio(audio_data)
Этот фрагмент возвращает аудиовиджет:

Визуализация аудио:
С помощью librosa.display.waveplot можно построить график массива аудио:
%matplotlib inline import matplotlib.pyplot as plt import librosa.display plt.figure(figsize=(14, 5)) librosa.display.waveplot(x, sr=sr)
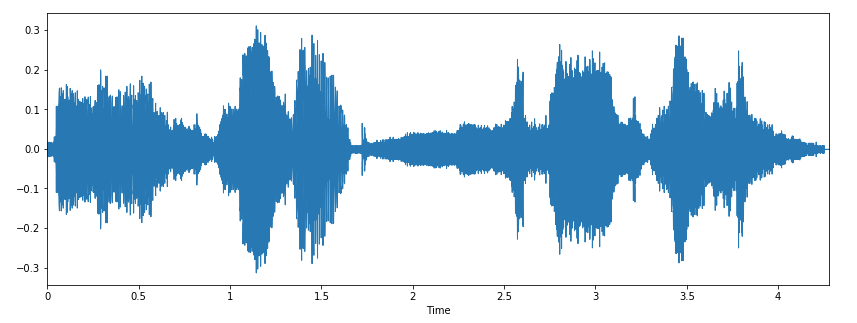
Ниже представлен график управления амплитудой формы волны:
Cпектрограмма
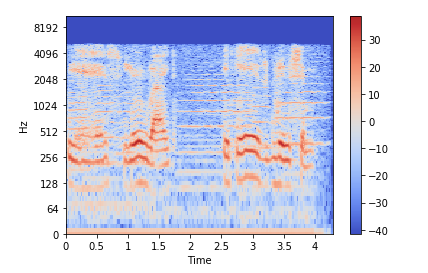
Спектрограмма — это визуальный способ представления уровня или «громкости» сигнала во времени на различных частотах, присутствующих в форме волны. Обычно изображается в виде тепловой карты.
Отобразить спектрограмму можно с помощью librosa.display.specshow.
X = librosa.stft(x) Xdb = librosa.amplitude_to_db(abs(X)) plt.figure(figsize=(14, 5)) librosa.display.specshow(Xdb, sr=sr, x_axis='time', y_axis='hz') plt.colorbar()
.stft() преобразует данные в кратковременное преобразование Фурье. С помощью STFT можно определить амплитуду различных частот, воспроизводимых в данный момент времени аудиосигнала. Для отображения спектрограммы используется .specshow.
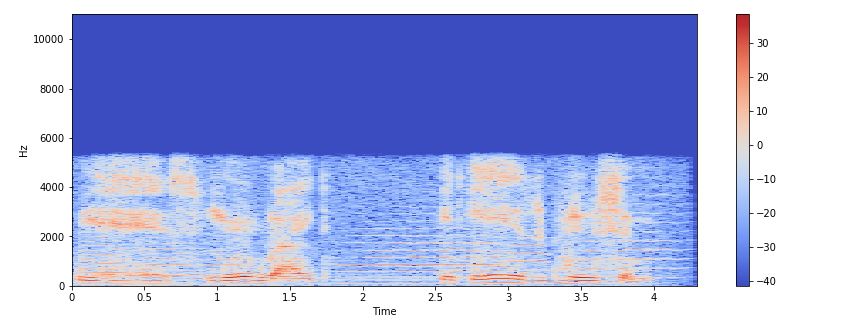
На вертикальной оси показаны частоты (от 0 до 10 кГц), а на горизонтальной — время. Поскольку все действие происходит в нижней части спектра, мы можем преобразовать ось частот в логарифмическую.
librosa.display.specshow(Xdb, sr=sr, x_axis='time', y_axis='log') plt.colorbar()
Создание аудиосигнала:
import numpy as np
sr = 22050 # частота дискретизации
T = 5.0 # секунды
t = np.linspace(0, T, int(T*sr), endpoint=False) # переменная времени
x = 0.5*np.sin(2*np.pi*220*t) # чистая синусоидная волна при 220 Гц
# проигрывание аудио
ipd.Audio(x, rate=sr) # загрузка массива NumPy
# сохранение аудио
librosa.output.write_wav('tone_220.wav', x, sr)
Извлечение признаков из аудио сигнала
Каждый аудиосигнал состоит из множества признаков. Мы будем извлекать только те характеристики, которые относятся к решаемой нами проблеме. Этот процесс называется извлечением признаков. Рассмотрим некоторые из них подробнее.
Спектральные (частотные) признаки получаются путем преобразования временного сигнала в частотную область с помощью преобразования Фурье. К ним относятся частота основного тона, частотные компоненты, спектральный центроид, спектральный поток, спектральная плотность, спектральный спад и т.д.
- Спектральный центроид
Указывает, на какой частоте сосредоточена энергия спектра или, другими словами, указывает, где расположен «центр масс» для звука. Схож со средневзвешенным значением:
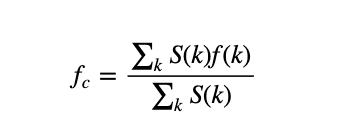
где S(k) — спектральная величина элемента разрешения k, а f(k) — частота элемента k.
librosa.feature.spectral_centroid вычисляет спектральный центроид для каждого фрейма в сигнале:
import sklearn
spectral_centroids = librosa.feature.spectral_centroid(x, sr=sr)[0]
spectral_centroids.shape
(775,)
# Вычисление временной переменной для визуализации
plt.figure(figsize=(12, 4))
frames = range(len(spectral_centroids))
t = librosa.frames_to_time(frames)
# Нормализация спектрального центроида для визуализации
def normalize(x, axis=0):
return sklearn.preprocessing.minmax_scale(x, axis=axis)
# Построение спектрального центроида вместе с формой волны
librosa.display.waveplot(x, sr=sr, alpha=0.4)
plt.plot(t, normalize(spectral_centroids), color='b')
.spectral_centroid возвращает массив со столбцами, равными количеству фреймов, представленных в семпле.
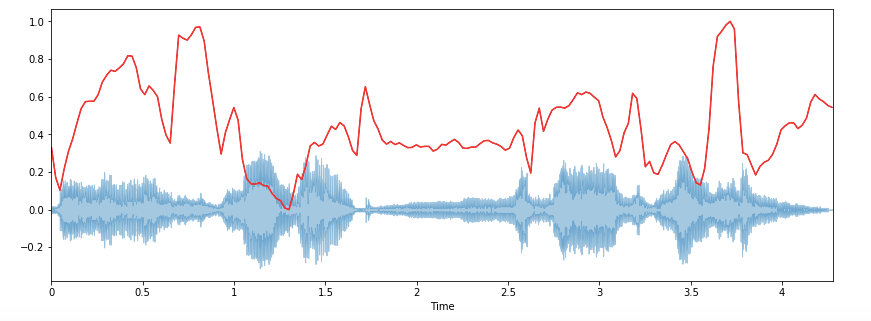
В начале спектрального центроида можно заметить подъем.
2. Спектральный спад
Это мера формы сигнала, представляющая собой частоту, в которой высокие частоты снижаются до 0. Чтобы получить ее, нужно рассчитать долю элементов в спектре мощности, где 85% ее мощности находится на более низких частотах.
librosa.feature.spectral_rolloff вычисляет частоту спада для каждого фрейма в сигнале:
spectral_rolloff = librosa.feature.spectral_rolloff(x+0.01, sr=sr)[0] plt.figure(figsize=(12, 4)) librosa.display.waveplot(x, sr=sr, alpha=0.4) plt.plot(t, normalize(spectral_rolloff), color='r')
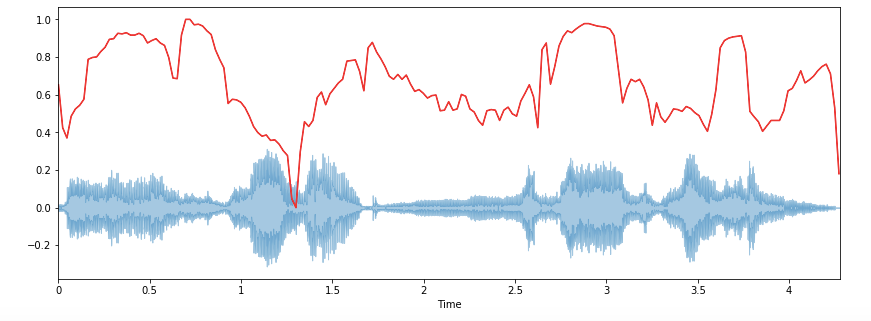
3. Спектральная ширина
Спектральная ширина определяется как ширина полосы света на половине максимальной точки (или полная ширина на половине максимума [FWHM]) и представлена двумя вертикальными красными линиями и λSB на оси длин волн.
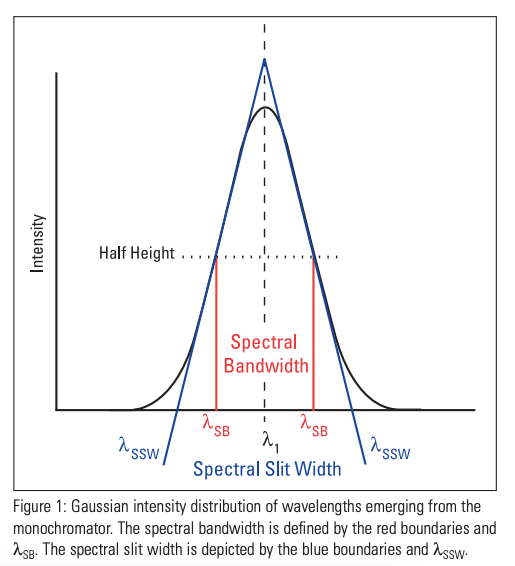 Фигура 1: Гауссово распределение интенсивности длин волн, выходящих из монохроматора. Спектральная полоса пропускания определяется красными границами и λSB. Ширина спектральной щели обозначена синими границами и λSSW.
Фигура 1: Гауссово распределение интенсивности длин волн, выходящих из монохроматора. Спектральная полоса пропускания определяется красными границами и λSB. Ширина спектральной щели обозначена синими границами и λSSW.librosa.feature.spectral_bandwidth вычисляет спектральную ширину порядка p:
spectral_bandwidth_2 = librosa.feature.spectral_bandwidth(x+0.01, sr=sr)[0]
spectral_bandwidth_3 = librosa.feature.spectral_bandwidth(x+0.01, sr=sr, p=3)[0]
spectral_bandwidth_4 = librosa.feature.spectral_bandwidth(x+0.01, sr=sr, p=4)[0]
plt.figure(figsize=(15, 9))
librosa.display.waveplot(x, sr=sr, alpha=0.4)
plt.plot(t, normalize(spectral_bandwidth_2), color='r')
plt.plot(t, normalize(spectral_bandwidth_3), color='g')
plt.plot(t, normalize(spectral_bandwidth_4), color='y')
plt.legend(('p = 2', 'p = 3', 'p = 4'))
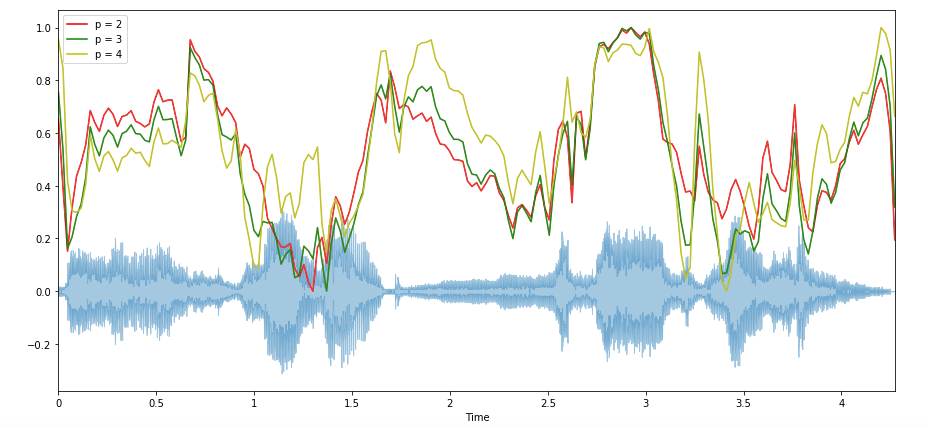
4. Скорость пересечения нуля
Простой способ измерения гладкости сигнала — вычисление числа пересечений нуля в пределах сегмента этого сигнала. Голосовой сигнал колеблется медленно. Например, сигнал 100 Гц будет пересекать ноль 100 раз в секунду, тогда как «немой» фрикативный сигнал может иметь 3000 пересечений нуля в секунду.
 Формула для расчета скорости пересечения нуля, где St — сигнал длины t, II{X} — функция-индикатор (=1 if X true, else =0).
Формула для расчета скорости пересечения нуля, где St — сигнал длины t, II{X} — функция-индикатор (=1 if X true, else =0).Более высокие значения наблюдаются в таких высоко ударных звуках, как в металле и роке. Теперь визуализируем этот процесс и рассмотрим вычисление скорости пересечения нуля.
x, sr = librosa.load('/../../gruesome.wav')
# Построение графика сигнала:
plt.figure(figsize=(14, 5))
librosa.display.waveplot(x, sr=sr)
# Увеличение масштаба:
n0 = 9000
n1 = 9100
plt.figure(figsize=(14, 5))
plt.plot(x[n0:n1])
plt.grid()
Увеличение масштаба:
n0 = 9000 n1 = 9100 plt.figure(figsize=(14, 5)) plt.plot(x[n0:n1]) plt.grid()
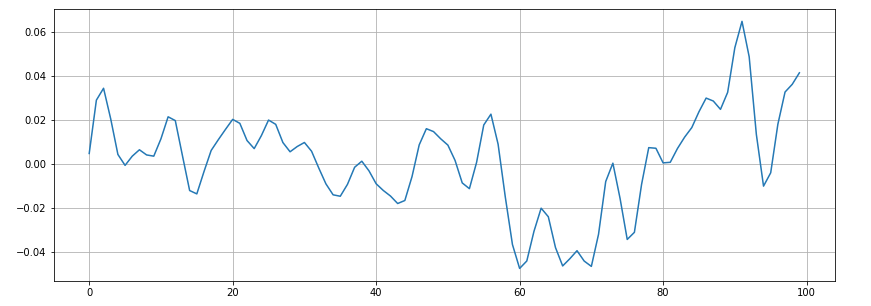
Здесь примерно 16 пересечений нуля. Проверим это с помощью Librosa.
zero_crossings = librosa.zero_crossings(x[n0:n1], pad=False) print(sum(zero_crossings))#16
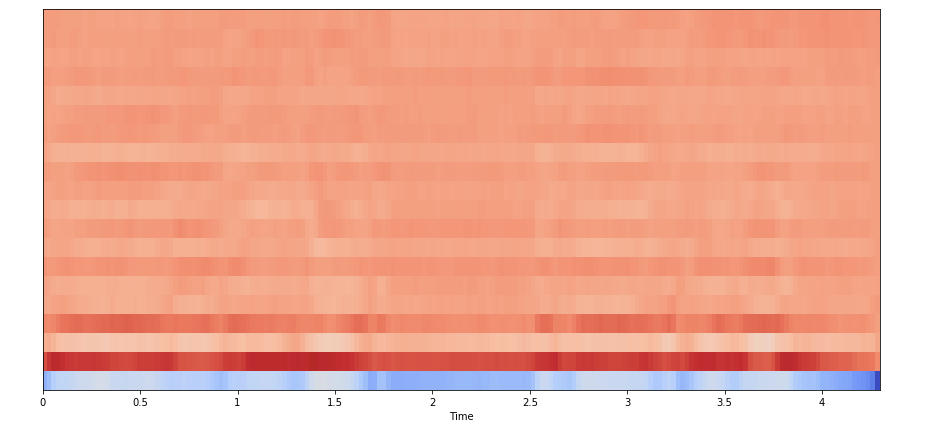
5. Мел-частотные кепстральные коэффициенты (MFCC)
Представляют собой небольшой набор признаков (обычно около 10–20), которые кратко описывают общую форму спектральной огибающей. Они моделируют характеристики человеческого голоса.
mfccs = librosa.feature.mfcc(x, sr=fs) print(mfccs.shape) (20, 97) # Отображение MFCC: plt.figure(figsize=(15, 7)) librosa.display.specshow(mfccs, sr=sr, x_axis='time')
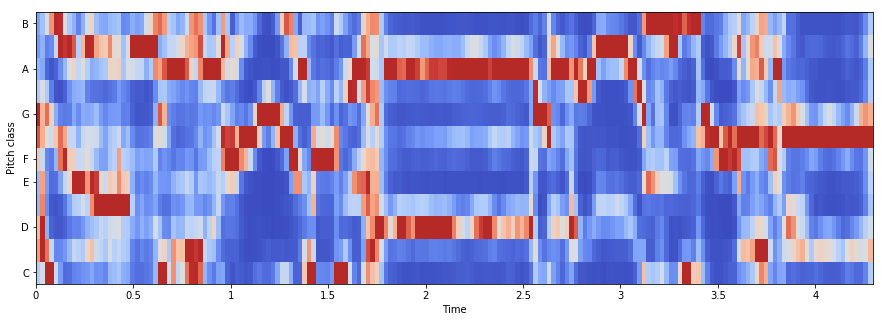
6. Цветность
Признак или вектор цветности обычно представлен вектором признаков из 12 элементов, в котором указано количество энергии каждого высотного класса {C, C#, D, D#, E, …, B} в сигнале. Используется для описания меры сходства между музыкальными произведениями.
librosa.feature.chroma_stft используется для вычисления признаков цветности.
chromagram = librosa.feature.chroma_stft(x, sr=sr, hop_length=hop_length) plt.figure(figsize=(15, 5)) librosa.display.specshow(chromagram, x_axis='time', y_axis='chroma', hop_length=hop_length, cmap='coolwarm')
Мы разобрались, как работать с аудиоданными и извлекать важные функции с помощью python. Теперь переходим к использованию этих функций и построению модели ANN для классификации жанров музыки.
Классификация жанров музыки с помощью ANN

Набор данных состоит из 1000 звуковых треков, длина каждого составляет 30 секунд. Он содержит 10 жанров, каждый из которых представлен 100 треками. Все дорожки — это монофонические 16-битные аудиофайлы 22050 Гц в формате .wav.
Жанры, представленные в наборе:
- Блюз
- Классика
- Кантри
- Диско
- Хип-хоп
- Джаз
- Метал
- Поп
- Регги
- Рок
Для работы с нейронными сетями мы будем использовать Google Colab — бесплатный сервис, предоставляющий GPU и TPU в качестве сред выполнения.
План:
В первую очередь нужно преобразовать аудиофайлы в изображения формата PNG (спектрограммы). Затем из них нужно извлечь значимые характеристики: MFCC, спектральный центроид, скорость пересечения нуля, частоты цветности, спад спектра.
После извлечения признаки можно добавить в файл CSV, чтобы ANN можно было использовать для классификации.
Приступим!
- Извлекаем и загружаем данные в Google Drive, а затем подключаем диск в Colab.
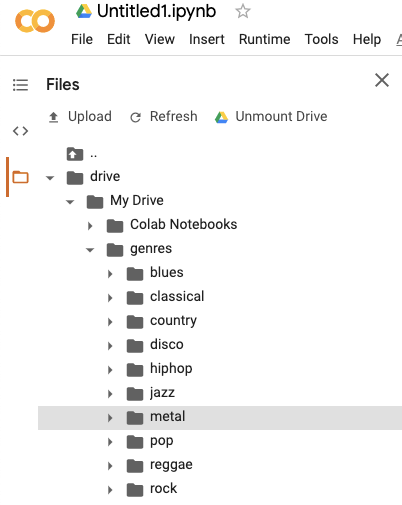 Структура директорий Google Colab после загрузки данных.
Структура директорий Google Colab после загрузки данных.2. Импортируем все необходимые библиотеки.
import librosa
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import os
from PIL import Image
import pathlib
import csv
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
import keras
from keras import layers
from keras import layers
import keras
from keras.models import Sequential
import warnings
warnings.filterwarnings('ignore')
3. Теперь конвертируем файлы аудиоданных в PNG или извлекаем спектрограмму для каждого аудио.
cmap = plt.get_cmap('inferno')
plt.figure(figsize=(8,8))
genres = 'blues classical country disco hiphop jazz metal pop reggae rock'.split()
for g in genres:
pathlib.Path(f'img_data/{g}').mkdir(parents=True, exist_ok=True)
for filename in os.listdir(f'./drive/My Drive/genres/{g}'):
songname = f'./drive/My Drive/genres/{g}/{filename}'
y, sr = librosa.load(songname, mono=True, duration=5)
plt.specgram(y, NFFT=2048, Fs=2, Fc=0, noverlap=128, cmap=cmap, sides='default', mode='default', scale='dB');
plt.axis('off');
plt.savefig(f'img_data/{g}/{filename[:-3].replace(".", "")}.png')
plt.clf()
Спектрограмма семпла песни в жанре блюз:
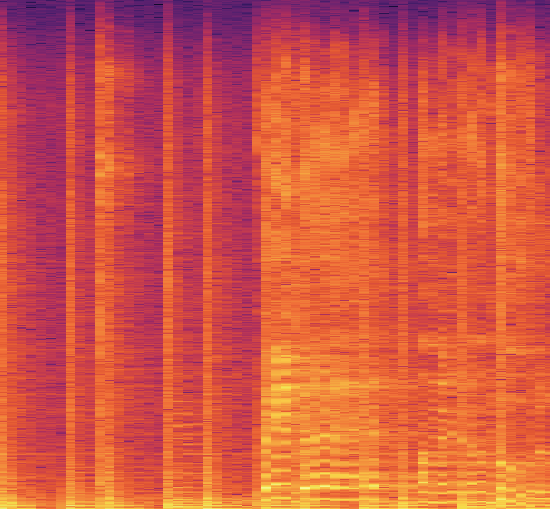
Преобразование аудиофайлов в соответствующие спектрограммы упрощает извлечение функций.
Создание заголовка для файла CSV.
header = 'filename chroma_stft rmse spectral_centroid spectral_bandwidth rolloff zero_crossing_rate'
for i in range(1, 21):
header += f' mfcc{i}'
header += ' label'
header = header.split()
5. Извлекаем признаки из спектрограммы: MFCC, спектральный центроид, частоту пересечения нуля, частоты цветности и спад спектра.
file = open('dataset.csv', 'w', newline='')
with file:
writer = csv.writer(file)
writer.writerow(header)
genres = 'blues classical country disco hiphop jazz metal pop reggae rock'.split()
for g in genres:
for filename in os.listdir(f'./drive/My Drive/genres/{g}'):
songname = f'./drive/My Drive/genres/{g}/{filename}'
y, sr = librosa.load(songname, mono=True, duration=30)
rmse = librosa.feature.rmse(y=y)
chroma_stft = librosa.feature.chroma_stft(y=y, sr=sr)
spec_cent = librosa.feature.spectral_centroid(y=y, sr=sr)
spec_bw = librosa.feature.spectral_bandwidth(y=y, sr=sr)
rolloff = librosa.feature.spectral_rolloff(y=y, sr=sr)
zcr = librosa.feature.zero_crossing_rate(y)
mfcc = librosa.feature.mfcc(y=y, sr=sr)
to_append = f'{filename} {np.mean(chroma_stft)} {np.mean(rmse)} {np.mean(spec_cent)} {np.mean(spec_bw)} {np.mean(rolloff)} {np.mean(zcr)}'
for e in mfcc:
to_append += f' {np.mean(e)}'
to_append += f' {g}'
file = open('dataset.csv', 'a', newline='')
with file:
writer = csv.writer(file)
writer.writerow(to_append.split())
6. Выполняем предварительную обработку данных, которая включает загрузку данных CSV, создание меток, масштабирование признаков и разбивку данных на наборы для обучения и тестирования.
data = pd.read_csv('dataset.csv')
data.head()
# Удаление ненужных столбцов
data = data.drop(['filename'],axis=1)
# Создание меток
genre_list = data.iloc[:, -1]
encoder = LabelEncoder()
y = encoder.fit_transform(genre_list)
# Масштабирование столбцов признаков
scaler = StandardScaler()
X = scaler.fit_transform(np.array(data.iloc[:, :-1], dtype = float))
# Разделение данных на обучающий и тестовый набор
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
7. Создаем модель ANN.
model = Sequential()
model.add(layers.Dense(256, activation='relu', input_shape=(X_train.shape[1],)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
8. Подгоняем модель:
classifier = model.fit(X_train,
y_train,
epochs=100,
batch_size=128)
После 100 эпох точность составляет 0,67.
Заключение
На этом первая часть подходит к концу. Мы провели анализ аудиоданных, извлекли важные признаки, а также реализовали ANN для классификации музыкальных жанров.
Во второй части попробуем выполнить то же самое с помощью сверточных нейронных сетей на спектрограмме.
Специально для сайта ITWORLD.UZ. Новость взята с сайта NOP::Nuances of programming